剑指 Offer 题解
前言
本文档中所有内容均采用 CC BY-NC 4.0 许可协议。
你可以复制共享、演绎创作,但不得用于商业目的。
本文档起源于本人于 $2020$ 年 $4$ 月起在 LeetCode 中《剑指 Offer》 所做的笔记。
看别人题解时的状态:一看就会,一听就懂,一做就错。
于是决定采用边阅读,边手敲题解,就算抄我也要抄一遍的方式进行学习,使用这种方法确实有一定作用。在手敲的过程中往往会有一些独特的体会以及更深刻的记忆,有时候自己也补上几句,久而久之,断断续续过去了三四个月,随着秋招的全面开启,这份笔记也越来越长,逐渐变成了现在这个样子。
$NOTE$: 本文档仅用于个人学习目的,旨在为准备校招的同学们以及其他对算法感兴趣的朋友提供一份便利,同时为了宣传 LeetCode-Krahets 的智慧结晶。
因为,这么精致的内容不让更多人看到实在是太说不过去了!
喜欢网页版的同学建议前往大佬的博客,其中有许多更形象生动的 $GIF$ 图。
喜欢 $PDF$ 的同学自然推荐这个。
我不是知识的生产者,只是知识的搬运工。
写于 $2020$ 年 $8$ 月 $9$ 日 $22$ 时 $35$ 分。
致谢
Credits are Krahets ‘s!
此中题解大部分出自 $LeetCode-Krahets$,大佬博客 $Krahets’s Blog$。
第一次看到大佬的题解时就有一种赏心悦目的感觉,排版精良,一丝不苟,哪怕只是一个再寻常不过的数字 $0$ 都会用 $LaTex$ 所修饰。毕竟,态度决定高度,细节决定成败。
本文中仍然存在很多问题,包括但不限于排版风格尚未完全统一、中英文标点符号不恰当、汉字错误、部分数学内容没有被 $LaTex$ 所渲染,以后将会逐渐完善。
可以说,如果不是这位大佬严谨细致题解,我很难坚持把 $LeetCode$ 上《剑指 $Offer$》系列题目看一遍。每当有题目没有头绪时,习惯性地在题解中寻找大佬的头像,阅读完后总有一种醍醐灌顶的感觉,感慨:山重水复疑无路,柳暗花明又一村。
题目来源
其他参考
- CS-Notes - 剑指Offer题解
- 《剑指Offer:名企面试官精讲典型编程题》,何海涛。
Tips
链表结点定义
1 | /** |
二叉树节点定义
1 | /** |
名词约定
- 链表中的 $Node$ 中文为 结点;
- 树中的 $TreeNode$ 中文为 节点。
经验
很多考研的同学都知道下面这个口诀
$$
🐶-sin 🐶 \approx \frac{1}{6}🐶^3 ,\quad 🐶 \rightarrow 0
$$
算法里针对某类特定的题也应该有类似的口诀, 比如:
- 看到有序数组的问题首先想到二分法;
- 二叉搜索树中:二叉搜索树的中序遍历结果时递增序列;
- 关于搜索问题必须想到 $DFS$、$BFS$;
- 想到以后再添加$\dots$
3. 数组中重复的数字
题目描述
在一个长度为 $n$ 的数组里的所有数字都在 $0$ 到 $n-1$ 的范围内。数组中某些数字是重复的,但不知道有几个数字是重复的,也不知道每个数字重复几次。请找出数组中任意一个重复的数字。
1 | Input: |
Solution 1 - 计数
采用“计数”的思想,申请一个长度为 $n$ 的数组 validation (当然也可以用 map or set ,但是数组效率更高一些),刚申请时每个元素都为 $0$,此时遍历一遍原数组,将原数组 nums 中的元素作为 validation 中的下标,并将 validation 中的元素加 $1$ ,表示元素出现了一次。在将原数组扫描一遍后,validation 中记录了每个元素出现的次数,再扫描一遍 validation,凡是 $\ge 1$ 的元素均为重复元素,返回第一个 $\ge 1$ 的元素即可。
1 | public int findRepeatNumber(int[] nums) { |
- 时间复杂度: $O(n)$。
- 空间复杂度: $O(n)$。
Solution 2 - 遍历一次
对于这种数组元素在$ [0, n-1]$ 范围内的问题,可以将值为 $i$ 的元素调整到第 $i$ 个位置上进行求解。本题要求找出重复的数字,因此在调整过程中,如果第 $i$ 位置上已经有一个值为 $i$ 的元素,就可以知道 $i$ 值重复。
1 | public int findRepeatNumber(int[] nums) { |
- 时间复杂度: $O(n)$。
- 空间复杂度: $O(1)$。
4. 二维数组中的查找
题目描述
在一个 $m\times n$ 的二维数组中,每一行都按照从左到右递增的顺序排序,每一列都按照从上到下递增的顺序排序。请完成一个函数,输入这样的一个二维数组和一个整数,判断数组中是否含有该整数。
1 | Consider the following matrix: |
Solution - 逼近
利用二维数组每一行从左到右递增,每一列从上到下递增的特点,可以从数组右上角开始:
- 如果扫描到的元素比
target小,则在当前列从上到下搜索; - 如果扫描到的元素比
target大,则在当前行从右向左搜索。
1 | public boolean findNumberIn2DArray(int target, int [][] matrix) { |
- 时间复杂度: $O(rows+cols)$。
- 空间复杂度: $O(1)$。
5. 替换空格
题目描述
将一个字符串中的空格替换成 "%20"。
1 | Input: |
Solution 1 - “倒排索引”
① 在字符串尾部填充任意字符,使得字符串的长度等于替换之后的长度。因为一个空格要替换成三个字符(%20),所以当遍历到一个空格时,需要在尾部填充两个任意字符。
② 令 $P1$ 指向字符串原来的末尾位置,$P2$ 指向字符串现在的末尾位置。$P1$ 和 $P2$ 从后向前遍历,当 $P1$ 遍历到一个空格时,就需要令 $P2$ 指向的位置依次填充 02%(注意是逆序的),否则就填充上 $P1$ 指向字符的值。从后向前遍历是为了在改变 $P2$ 所指向的内容时,不会影响到 $P1$ 遍历原来字符串的内容。
③ 当 $P2$ 遇到 $P1$ 时($P2 \le P1$),或者遍历结束($P1 < 0$),退出。
1 | public String replaceSpace(String s) { |
- 时间复杂度: $O(n)$。
- 空间复杂度: $O(n)$。
Solution 2 - 遍历添加
1 | public String replaceSpace(String s) { |
- 时间复杂度: $O(n)$。
- 空间复杂度: $O(n)$。
6. 从尾到头打印链表
题目描述
输入一个链表的头节点,从尾到头反过来返回每个节点的值(用数组返回)。
Solution 1 - 栈
利用“栈”先进后出的特点,可以实现逆序的效果。
在 $JDK$ 的使用文档里,对于 java.util.Stack 有这样一句话:
“A more complete and consistent set of LIFO stack operations is provided by the Deque interface and its implementations, which should be used in preference to this class. ” For example:
1 | Deque<Integer> stack = new ArrayDeque<Integer>(); |
意思就是推荐使用 $Deque$ 来作为 $Stack$ 的替代品,用 $ArrayDeque$ 作为其实现类,也可以使用 $LinkedList$,具体问题具体分析,看是增删多,还是查询多。
1 | public int[] reversePrint(ListNode head) { |
- 时间复杂度: $O(n)$。
- 空间复杂度: $O(n)$。
Solution 2 - 递归
要逆序打印链表 1->2->3(3,2,1),可以先逆序打印链表 2->3(3,2),最后再打印第一个结点 1。而链表 2->3 可以看成一个新的链表,要逆序打印该链表可以继续使用求解函数,也就是在求解函数中调用自己,这就是递归函数。
1 | public class Solution { |
- 时间复杂度: $O(n)$。
- 空间复杂度: $O(n)$。
Solution 3 - 头插法
遍历原链表,将原链表中的每个元素以头插法的方式插入到一个辅助链表中,此时辅助链表中的元素恰好为原链表中的元素逆序后的结果。再遍历辅助链表存储每个元素即可。
在此过程中需要维护一个头结点,维护待插入结点的下一个结点,如果不维护下一个结点的话,将会丢失下一个要插入元素。
1 | /** |
- 时间复杂度: $O(n)$。
- 空间复杂度: $O(n)$。
Solution 4 - 两次遍历
1 | public int[] reversePrint(ListNode head) { |
- 时间复杂度: $O(n)$。
- 空间复杂度: $O(n)$。
7(🌲) . 重建二叉树
题目描述
输入某二叉树的前序遍历和中序遍历的结果,请重建出该二叉树。假设输入的前序遍历和中序遍历的结果中都不含重复的数字。例如输入前序遍历序列 ${1,2,4,7,3,5,6,8}$ 和中序遍历序列 ${4,7,2,1,5,3,8,6}$ ,则重建二叉树并返回。
Solution - 递归
前序遍历:根、左、右
中序遍历:左、根、右
根据前序遍历与中序遍历可以确定一棵二叉树,有以下几个要点(假设序列如题目描述中):
- 前序遍历的首个结点为当前子树的根节点 $root$,即 $1$
- 在中序遍历中找到当前子树的根节点,那么处于根节点左边的则为左子树中的结点,处于根节点右边的则为左、右子树中的节点。将中序遍历划分为
[left | root | right],即[4,7,2 | 1 | 5, 3, 8, 6] - 根据中序遍历
[left | root | right]中的左右子树中节点的数量,再将前序遍历划分为[root | left | right],即[1 | 2, 4, 7 | 3, 5, 6, 8] - 经过以上三步后可以确定三个结点,即
- 根节点
root(1) - 左子树根节点
root.left(2) - 右子树根节点
root.right(3)
- 根节点
递归解析
递推参数: 前序遍历中根节点的索引
preRoot、中序遍历左边界inLeft、中序遍历右边界inRight终止条件: 当
inLeft > inRight,子树中序遍历为空,说明已经越过叶子节点,此时返回null。递推工作:
- 建立根节点
root: 值为前序遍历中索引为preRoot的节点值。 - 搜索根节点
root在中序遍历的索引i: 为了提升搜索效率,使用哈希表dic预存储中序遍历的值与索引的映射关系,每次搜索的时间复杂度为 $O(1)$; - 构建根节点
root的左子树和右子树: 通过调用recur()方法开启下一层递归。- 左子树: 根节点索引为
preRoot + 1,中序遍历的左子树的左右边界分别为inLeft和i - 1; - 右子树: 根节点索引为
i - inLeft + preRoot + 1(即:根节点索引 $+$ 左子树长度 $ + 1$),中序遍历的右子树的左右边界分别为i + 1和inRight。
- 左子树: 根节点索引为
- 建立根节点
返回值: 返回
root,含义是当前递归层级建立的根节点root为上一层递归的根节点的左或右子节点。
1 | class Solution { |
- 时间复杂度:$O(n)$,遍历中序序列 $O(n)$,递归共建立 $n$ 个节点,每层递归中的节点建立、搜索操作占用 $O(1)$,因此递归占用 $O(n)$。
- 空间复杂度:$O(n)$,$HashMap$ 使用 $O(n)$;递归操作递归栈使用 $O(n)$。
8(🌲). 二叉树的下一个结点
题目描述
给定一个二叉树和其中的一个节点,请找出中序遍历顺序的下一个结点并且返回。注意,树中的节点不仅包含左右子节点,同时包含指向父节点的指针。节点结构如下:
1 | public class TreeLinkNode { |
Solution
中序遍历的顺序是左、根、右,所以中序遍历中的第一个节点位于二叉树中最左侧。在中序遍历的过程中:
- 如果一个节点 $root$ 的右子树非空,那么它的下一节点是右子树中的最左节点;
- 否则,向上回溯寻找第一个左指针指向 $root$ 的祖先节点。
1 | public TreeLinkNode GetNext(TreeLinkNode pNode) { |
- 时间复杂度: $O(n)$。
- 空间复杂度: $O(1)$。
9. 用两个栈实现队列
题目描述
用两个栈实现一个队列。队列的声明如下,请实现它的两个函数 appendTail 和 deleteHead ,分别完成在队列尾部插入整数和在队列头部删除整数的功能(若队列中没有元素,deleteHead 操作返回 -1)。
1 | 输入: |
Solution - 辅助栈
队列为先进先出,栈为先进后出,那么利用两个栈,一个作为入栈 stack1,一个作为出栈 stack2,便可以实现队列的先进先出功能。
- 入队操作:将元素压入
stack1中。 - 出队操作:首先将
stack1中的元素弹出并且压入到stack2中,再将stack2中的元素弹出并压入到stack1中。
1 | /** |
- 时间复杂度:$O(n)$,
appendTail用时 $O(1)$,deleteHead用时 $O(n)$。 - 空间复杂度:$O(n)$,最坏情况下,$A、B$ 共保存 $n$ 个元素。
10 - I. 斐波那契数列
接下里的 10-II ~ 10-IV 都是斐波那契数列的衍生题。
题目描述
写一个函数,输入 $n$ ,求斐波那契($Fibonacci$)数列的第 $n$ 项。斐波那契数列的定义如下:
1 | F(0) = 0, F(1) = 1 |
斐波那契数列由 $0$ 和 $1$ 开始,之后的斐波那契数就是由之前的两数相加而得出。
答案需要取模 $1e9+7$($1000000007$),如计算初始结果为:$1000000008$,请返回 $1$。
Solution 1 - 暴力法(自顶向下)
1 | // 暴力递归 不可取 |
- 时间复杂度:$O(2^n)$。
Solution 2 - 动态规划(自下而上)
1 | // 动态规划 - 状态转移方程 |
- 时间复杂度:$O(n)$。
- 空间复杂度:$O(n)$。
Solution 3 - 记忆化搜索
1 | // 考虑到第 i 项只与第 i-1 和第 i-2 项有关 |
- 时间复杂度:$O(n)$。
- 空间复杂度:$O(1)$。
Solution 4 - 快速幂
根据斐波那契数列自身的性质,可以构造如下关系式
$$
\begin{cases}
F_2 = F_1 +F_0 \
F_1 = F_1
\end{cases}{\tag 1}
$$
而表达式 $(1)$ 可以用矩阵表示为
$$
\begin{bmatrix} F_2 \ F_1 \end{bmatrix} = \begin{bmatrix} 1 & 1 \ 1 & 0 \end{bmatrix} \times \begin{bmatrix} F_1 \ F_0 \end{bmatrix}
$$
那么
$$
\begin{bmatrix} F_3 \ F_2 \end{bmatrix} = \begin{bmatrix} 1 & 1 \ 1 & 0 \end{bmatrix} \times \begin{bmatrix} F_2 \ F_1 \end{bmatrix}=\begin{bmatrix} 1 & 1 \ 1 & 0 \end{bmatrix}^2 \times \begin{bmatrix} F_2 \ F_1 \end{bmatrix}
$$
递推下去可以得到
$$
\begin{bmatrix} F_n \ F_{n-1} \end{bmatrix} = \begin{bmatrix} 1 & 1 \ 1 & 0 \end{bmatrix} \times \begin{bmatrix} F_2 \ F_1 \end{bmatrix} = \begin{bmatrix} 1 & 1 \ 1 & 0 \end{bmatrix}^{n-1} \times \begin{bmatrix} F_1 \ F_0 \end{bmatrix} = \begin{bmatrix} 1 & 1 \ 1 & 0 \end{bmatrix}^{n-1} \times \begin{bmatrix} 1 \ 0 \end{bmatrix}
$$Java实现矩阵比较麻烦,学有余力的同学可以看看。
- 时间复杂度:$O(\lg n)$。
10 - II. 青蛙跳台阶问题
题目描述
一只青蛙一次可以跳上 $1$ 级台阶,也可以跳上 $2$ 级台阶。求该青蛙跳上一个 $n$ 级的台阶总共有多少种跳法。
答案需要取模 $1e9+7$($1000000007$),如计算初始结果为:$1000000008$,请返回 $1$。
Solution - 记忆化搜索
真正的粉丝都是直奔 $Solution$ 🤓
此类求有多少可能性的题目一般都具有递推性质,即 $f(n)$ 依赖于 $f(1),f(2),\dots,f(n-1)$。
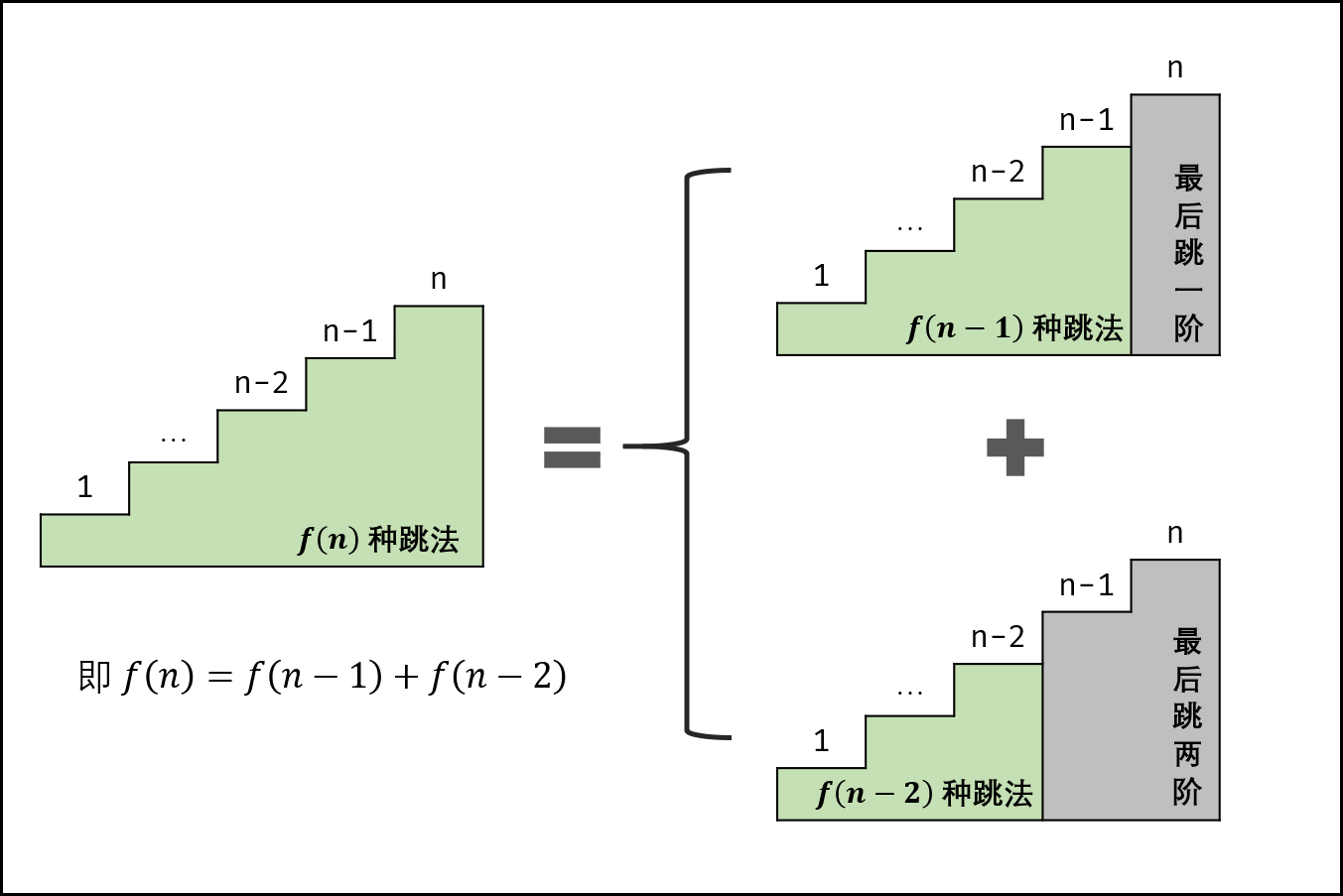
假设青蛙跳上第 $n$ 级台阶有 $f(n)$ 种方式,那它可以从第 $n-1$ 级台阶跳一级台阶,也可以从第 $n-2$ 级台阶一次跳两级台阶。也就是:
$$
f(n)=f(n-1)+f(n-2)
$$
这个递推式是不是和斐波那契递推式有点相似?但是它们的初值呢?
- 🐇 斐波那契: $f(0)=0,f(1)=f(2)=1$
- 🐸 青蛙跳: $f(0)=1,f(1)=1,f(2)=2$
1 | public int numWays(int n) { |
- 时间复杂度:$O(n)$。
- 空间复杂度:$O(1)$。
10 - III 变态跳台阶
题目描述
一只青蛙一次可以跳上 $1$ 级台阶,也可以跳上 $2$ 级 $\dots$ 它也可以跳上 $n$ 级。求该青蛙跳上一个 $n$ 级的台阶总共有多少种跳法。
Solution - 1: 数学推导
跳上 $n-1$ 级台阶,可以从 $n-2$ 级跳 $1$ 级上去,也可以从 $n-3$ 级跳 $2$ 级上去… 那么
$$
f(n-1) = f(n-2) + f(n-3) + \dots + f(0) {\tag 1}
$$
同样,跳上 $n$ 级台阶,可以从 $n-1$ 级跳 $1$ 级上去,也可以从 $n-2$ 级跳 $2$ 级上去… ,那么
$$
f(n) = f(n-1) + f(n-2) + \dots + f(0) {\tag 2}
$$
由 $(2) - (1)$ 可得 $f(n)=2f(n-1)$。
所以,以 $1$ 为首项,$2$ 为公比的等比数列。
1 | public int JumpFloorII(int target) { |
- 时间复杂度:$O(1)$。
- 空间复杂度:$O(1)$。
Solution 2 - 动态规划
1 | public int JumpFloorII(int target) { |
- 时间复杂度:$O(n^2)$。
- 空间复杂度:$O(n)$。
10 - IV 矩形覆盖
可以用 $2\times1$ 的小矩形横着或者竖着去覆盖更大的矩形。请问用 $n$ 个 $2\times 1$ 的小矩形无重叠地覆盖一个 $2\times n$ 的大矩形,总共有多少种方法?
Solution - 动态规划
当 $n$ 为 $1$ 时,只有一种覆盖方法;当 $n$ 为 $2$ 时,有两种覆盖方法。
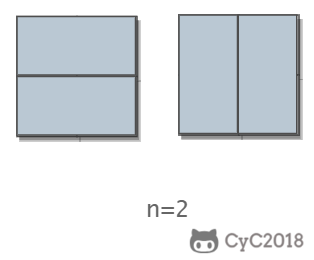
要覆盖 $2 \times n$ 的矩形,可以先覆盖 $2 \times 1$ ,再覆盖 $2 \times (n-1)$ 的矩形,或者先覆盖 $2 \times 2$ ,再覆盖 $2 \times (n-2)$ 的矩形。而覆盖 $2\times (n-1)$ 和 $2\times (n-2)$ 的矩形可以看成是子问题。
$$
f(n)=
\begin{cases}
1 &, n=1 \
2 &, n=2 \
f(n-1)+f(n-2) &, n\ge3
\end{cases}
$$
1 | public int RectCover(int target) { |
- 时间复杂度:$O(n)$。
- 空间复杂度:$O(1)$。
11. 旋转数组的最小数字
题目描述
把一个数组最开始的若干个元素搬到数组的末尾,我们称之为数组的旋转。输入一个非递减排序的数组的一个旋转,输出旋转数组的最小元素。例如数组 $[3,4,5,1,2]$ 为 $[1,2,3,4,5]$ 的一个旋转,该数组的最小值为 $1$。
1 | 输入:[3,4,5,1,2] |
$NOTE$:给出的所有元素都大于 $0$,若数组大小为 $0$,请返回 $0$。
Solution - 1 暴力搜索
不就是要求数组里的最小数字嘛,我直接搜索一遍不行吗?净拿修饰词扰乱军心!
1 | public int minArray(int[] numbers) { |
- 时间复杂度:$O(n)$。
- 空间复杂度:$O(1)$。
Solution - 2 二分搜索
使用暴力搜索,遍历一遍数组就可以获得数组中的最小元素,时间复杂度为 $O(n)$,空间复杂度为 $O(1)$。但是题目描述了那么多,肯定不是为了让你使用暴力搜索的。
如果利用数组部分有序这个特点,可以将时间复杂度降低到 $O(\lg n)$。
在数组操作中,只要读出了 有序 的明示或者暗示,无论数据类型是整型还是字符串,首先想到 二分搜索。
在示例 $[3,4,5,1,2]$ 中,可以把 $1$ 看作一个 波谷,也可以认为是一个转折点。可以看到,在 $1$ 的左侧的 $[3,4,5]$ 是有序(升序)的,而在包含 $1$ 在内的 $[1,2]$ 也是有序(升序)的,所以可以认为转折点将数组分成了两个有序数组。
设置 start,end,mid 三个变量,分别代表数组左右两端,以及中间。
- $numbers[mid] > numbers[end]$ : 如果是升序,
mid应该小于end,但是这里是大于,说明mid左侧都是有序的,旋转点 $x$ 一定在 $[mid+1, end]$ 之间,所以接下来应该在 $[mid+1, end]$ 之间寻找旋转点,同时修改start = mid + 1。 - $numbers[mid] < numbers[end]$ : 说明
mid右侧是有序的,而旋转点 $x$ 一定在 $[start, mid]$ 之间,所以接下来应该在之 $[start, mid]$ 间寻找旋转点,同时修改end = mid。 - $numbers[mid] == numbers[end]$ :例如 $[5,0,1,1,1,1]$,执行
end--缩小搜索区间。
1 | public int minArray(int[] numbers) { |
- 时间复杂度:$O(\lg n)$,但是在 $[1,1,1,1,1,1,\dots]$ 这种特例下,会退化成 $O(n)$。
- 时间复杂度:$O(1)$。
12. 矩阵中的路径
设计一个函数,用来判断在一个矩阵中是否存在一条包含某字符串所有字符的路径。
路径可以从矩阵中的任意一格开始,每一步可以在矩阵中向左、右、上、下移动一格。如果一条路径经过了矩阵的某一格,那么该路径不能再次进入该格子。例如,在下面的 $3\times 4$ 的矩阵中包含一条字符串"bfce"的路径。
1 | [ |
但矩阵中不包含字符串"abfb"的路径,因为字符串的第一个字符 "b" 占据了矩阵中的第一行第二个格子之后,路径不能再次进入这个格子。
Solution - DFS
关于搜索问题,首先想到两种常用的搜索算法,$DFS$、$BFS$。
解题思路: 本问题是典型的矩阵搜索问题,可使用深度优先搜索($DFS$) $+$ 剪枝操作解决。
算法原理:
- 深度优先搜索: 可以理解为暴力方法遍历矩阵中所有字符串可能性,$DFS$ 通过递归,先朝一个方向搜索到底,再回溯至上个结点,沿一个之前未搜索过的方向搜索,如此反复。
- 剪枝: 在搜索中,遇到 这条路不可能和目标字符串匹配成功 的情况,则立即返回,称之为可行性剪枝。
算法流程
- 递归参数: 当前元素在矩阵
board中的行列索引i和j,当前目标字符在word中的索引k。 - 终止条件:
- 返回 $true$ : 字符串
word已全部匹配,即k = len(word) - 1; - 返回 $false$ : $(1)$ 行或列索引越界 $(2)$ 当前矩阵元素与目标字符不符 $(3)$ 当前矩阵元素已访问过。
- 返回 $true$ : 字符串
- 递推工作:
- 标记当前矩阵元素: 将
board[i][j]值暂存于变量tmp,并修改为字符/,代表此元素已访问过,防止之后搜索时重复访问。 - 搜索下一单元格: 朝当前元素的 上、下、左、右 四个方向开启下层递归,使用
||连接(或运算,代表只需要存在一条可行路径),并记录结果到res。 - 还原当前矩阵元素: 将
tmp暂存值还原至board[i][j]元素。
- 标记当前矩阵元素: 将
- 回溯返回值: 返回
res,代表是否搜索到目标字符串。
1 | public boolean exist(char[][] board, String word) { |
- 时间复杂度:$O(3^kmn)$,最差情况下,需要遍历矩阵中长度为 $k$ 字符串的所有解决方案,时间复杂度为 $O(3^k)$ ;矩阵中共有 $mn$ 个元素可做起始点,时间复杂度为 $O(mn)$ 。
- 空间复杂度:$O(k)$,搜索过程中的递归深度不超过 $k$ ,因此系统递归栈占用 $O(k)$ ,最坏情况下 $k=mn$ 。
13. 机器人的运动范围
题目描述
地上有一个 $m$ 行和 $n$ 列的方格。一个机器人从坐标 $(0,0)$ 的格子开始移动,每一次只能向左,右,上,下四个方向移动一格,但是不能进入行坐标和列坐标的数位之和大于 $k$ 的格子。 例如,当 $k$ 为 $18$ 时,机器人能够进入方格 $(35,37)$,因为 $3+5+3+7 = 18$。但是,它不能进入方格 $(35,38)$,因为 $3+5+3+8 = 19$。请问该机器人能够达到多少个格子?
1 | 输入:m = 2, n = 3, k = 1 |
本题与矩阵中的路径类似,是典型的矩阵搜索问题。此类问题通常可使用 深度优先搜索($DFS$) 或 广度优先搜索($BFS$)解决。
在介绍 $DFS / BFS$ 算法之前,为提升计算效率,首先讲述两项前置工作:数位之和计算、 搜索方向简化。
数位之和计算:
- 设某数字 $x$ ,向下取整符号 $//$ ,求余符号 $\odot$ ,则有:
- $x \odot 10$ : 得到 $x$ 的个位数字;
- $x // 10$ : 令 $x$ 的十进制数向右移动一位,即删除个位数字。
- 因此可通过循环求得数位和 $s$。
1 | def sum(s): |
- 由于机器人每次只能移动一格,因此每次只需要计算 $x$ 到 $x \pm 1$ 的数位和增量。本题说明 $1 \le n,m \le 100$ ,以下公式仅在此范围内适用。
- 数位和增量表达式: 设 $x$ 的数位和为 $s_x$ , $x+1$ 的数位和为 $s_{x+1}$
- 当 $(x+1)\odot 10 = 0$ 时: $s_{x+1}=s_x - 8$ ,例如 $19,20$ 的数位和分别为 $10,2$
- 当 $(x+1)\odot 10 \ne 0$ 时: $s_{x+1}=s_x + 1$ ,例如 $1,2$ 的数位和分别为 $1,2$
1 | (x + 1) % 10 != 0 ? s_x + 1 : s_x - 8 |
搜索方向简化
- 数位和特点: 根据数位和增量公式得知,数位和每逢 进位 突变一次。
- 解的三角形结构:
- 根据数位和特点,矩阵中 满足数位和的解 构成的几何形状形如多个 等腰直角三角形 ,每个三角形的直角顶点位于 $0,10,20,\dots,0,10,20,\dots$ 等数位和突变的矩阵索引处 。
- 三角形内的解虽然都满足数位和要求,但由于机器人每步只能走一个单元格,而三角形间不一定是连通的,因此机器人不一定能到达,称之为 不可达解 ; 同理,可到达的解称为 可达解 (本题求此解) 。
- 结论:根据可达解的结构,易推出机器人可仅通过向右和向下移动,访问所有可达解
- 三角形内部: 全部连通,易证;
- 两三角形连通处: 若某三角形内的解为可达解,则必与其左边或上边的三角形连通(即相交),即机器人必可从左边或上边走进此三角形。

Solution 1 - DFS
算法解析:
- 递归参数: 当前元素在矩阵中的行列索引 $i,j$ ,两者的数位和 $si,sj$ 。
- 终止条件: 当 $(1)$ 行列索引越界或 $(2)$ 数位和超出目标值 $k$ 或 $(3)$ 当前元素已访问过时,返回 $0$ ,代表不计入可达解。
- 递推工作:
- 标记当前单元格: 将索引 $(i,j)$ ,存入 $Set$
visited中,代表此单元格已被访问过。 - 搜索下一单元格: 计算当前元素的下、右两个方向元素的数位和,并开启下层递归。
- 标记当前单元格: 将索引 $(i,j)$ ,存入 $Set$
- 回溯返回值: 返回
1 + 右侧搜索的可达解总数 + 下方搜索的可达解总数,代表本单元格递归搜索的可达解总数。
1 | class Solution { |
- 时间复杂度:$O(mn)$,最差情况下需要遍历所有单元格。
- 空间复杂度:$O(mn)$,$Set$ 内存储所有单元格的索引。
Solution 2 - BFS
算法解析:
- 初始化: 将机器人初始点 $(0, 0)$ 加入队列
queue; - 迭代终止条件:
queue为空,代表已遍历完所有可达解。 - 迭代工作:
- 单元格出队: 将队首单元格的 索引、数位和 弹出,作为当前搜索单元格。
- 判断是否跳过: 当 $(1)$ 行列索引越界 $(2)$ 数位和超出目标值 $k$ $(3)$ 当前元素已访问过时,执行
continue。 - 标记当前单元格 :将单元格索引
(i, j)存入 $Set$visited中,代表此单元格 已被访问过 。 - 单元格入队: 将当前元素的 下方、右方 单元格的 索引、数位和 加入
queue。
- 返回值: $Set$
visited的长度len(visited),即可达解的数量。

1 | public int movingCount(int m, int n, int k) { |
- 时间复杂度:$O(mn)$,最差情况下需要遍历所有单元格。
- 空间复杂度:$O(mn)$,$Set$ 内存储所有单元格的索引。
14- I. 剪绳子
题目描述
给定一个正整数 $n$,将其拆分为至少两个正整数的和,并使这些整数的乘积最大化。 返回可以获得的最大乘积。
1 | 输入: 10 |
Solution 1 - 函数极值
- 将正整数 $n$ 拆分为 $a$ 个小数字: $n = n_1 + n_2 + \dots + n_a$;
- 本题等价于求解:$max(n_1 \times n_2 \times \dots n_a)$。
在均值不等式中有
$$
\frac{n_1 + n_2 + \dots + n_a}{a} \ge \sqrt{n_1n_2\dots n_a}
$$
当且仅当 $n_1=n_2=\dots = n_a$ 时等式成立。
推导
- 将绳子按照 $x$ 等分为 $a$ 段,即 $n = ax$ ,则其乘积为 $x^a$ 。观察等式 $(1)$ ,由于 $n$ 为常数,因此当 $x^{\frac{1}{x}}$ 取最大值时,乘积取到最大值。
$$
x^a=x^{\frac{n}{x}}=(x^{\frac{1}{x}})^n \tag{1}
$$
- 所以,将原问题转化为求 $y=x^{\frac{1}{x}}$ 的极大值,因此按照微积分中幂指函数微分求导的方法:
$$
\begin{align*}
两边同时取自然对数得: \quad lny &= \frac{1}{x}lnx\tag{2} \
隐函数求导: \quad \frac{1}{y}y^{‘}&=\frac{1-lnx}{x^2}\tag{3} \
回代\ y=x^{\frac{1}{x}}\ 得: \quad y^{‘}&=\frac{1-lnx}{x^2}x^{\frac{1}{x}}\tag{4}
\end{align*}
$$
令等式 $y^{‘}=0$ ,解得驻点 $x_0=e \approx 2.718$,由题意得:
- 当 $x\in (0,e]$ 时,$y^{‘}\ge0 $,所以 $y$ 单调递增;
- 当 $x \in [e, +\infty)$ 时,$y^{‘}\le0 $,所以 $y$ 单调递减。
所以,$x_0$ 为 $y$ 的极大值点。
- 根据题意可知切分长度需要为整数,因此取 $x=2$ 或 $x=3$ , 而
$$
y_{(3)}^6=(3^{\frac{1}{3}})^6 = 9 \
y_{(2)}^6=(2^{\frac{1}{2}})^6 = 8
$$
经过以上推导之后可以发现拆分规则:
- 最优:将数字 $n$ 拆分成尽可能多个 $3$,余数可能为 $0、1、2$;
- 次优:若余数为 $2$,则保留,不再拆分为 $1+1$;
- 最差:若余数为 $1$;则应把一份 $3+1$ 替换为 $2+2$。
算法流程:
- 当 $n \le 3$ 时,按照规则不应该拆分,但由于题目要求必须拆分,因为必须拆出一个因子 $1$,返回 $n-1$;
- 当 $n > 3$ 时,求 $n$ 除以 $3$ 的整数部分 $a$ 和余数部分 $b$ ,并分为以下三种情况:
- $b=0$,直接返回 $3^a$;
- $b=1$,将一个 $1+3$ 替换为 $2+2$,返回 $3^{a-1}\times 4$;
- $b=2$,返回 $3^a \times 2$。
1 | public int integerBreak(int n) { |
- 时间复杂度:$O(1)$。
- 空间复杂度:$O(1)$。
Solution 2 - 动态规划
对于正整数 $n$,当 $n \ge 2$ 时,可以拆分成两个正整数之和。假设 $k$ 是拆分出的第一个正整数,则剩余部分为 $n - k$, $n - k$ 可以不拆分,或者继续拆分成至少两个正整数之和。由于每个正整数对应的最大乘积取决于比它小的正整数的最大乘积,因此可用动态规划求解。
- 状态定义:设 $dp$ 数组为动态规划数组,$dp[i]$ 表示在将正整数 $i$ 拆分成至少两个正整数之和时,目前所有拆分数的最大乘积。
- 状态转移:对于正整数 $i$ ,假设拆出的数为 $j$ 则余下的部分为 $i-j$ ,而对于 $i-j$ 亦有两种选择,要么就此为止,要么继续拆。则
- 就此为止:此时乘积为 $j \times (i-j)$;
- 继续拆:即将 $i-j$ 继续拆分,此时乘积为 $j \times dp[i-j]$。
因此状态转移方程为:
$$
dp[i]=max(j\times (i - j), j * dp[i - j]), 1 \le j < i
$$
- 初始值:对于数字 $0$,不可拆,赋值为 $dp[0] = 0$,数字 $1$ 需要拆分成 $0$ 和 $1$,因此 $dp[1] = 0 \times 1 = 0$。
1 | public int cuttingRope(int n) { |
- 时间复杂度:$O(n^2)$,其中 $n$ 是给定的正整数。对于从 $2$ 到 $n$ 的每一个整数都要计算对应的 $dp$ 值,计算一个整数对应的 $dp$ 值需要 $O(n)$ 的时间复杂度,因此总的时间复杂度为 $O(n^2)$。
- 空间复杂度:$O(n)$,其中 $n$ 是给定的正整数。创建一个数组 $dp$,其长度为 $n + 1$。
14- II. 剪绳子 II
题目描述
给你一根长度为 $n$ 的绳子,请把绳子剪成整数长度的 $m$ 段($m、n$都是整数,$n>1$并且 $m>1$),每段绳子的长度记为 $k[0],k[1], \dots ,k[m - 1]$ 。请问 $k[0]\times k[1]\times \cdots \times k[m - 1]$ 可能的最大乘积是多少?
例如,当绳子的长度是 $8$ 时,我们把它剪成长度分别为 $2、3、3$ 的三段,此时得到的最大乘积是 $18$。
答案需要取模 $1e9+7(1000000007)$,如计算初始结果为:$1000000008$,请返回 $1$。
Solution - 二分法: 点我去看
1 | class Solution { |
- 时间复杂度:$O(log_2 N)$。其中 $N = a$,二分法为对数级别复杂度,每轮仅有求整、求余、次方运算。
- 空间复杂度:$O(1)$。变量 $a, b, p, x, rem$ 使用常数大小额外空间。
15. 二进制中 1 的个数
题目描述
输入一个整数,输出该数二进制表示中 $1$ 的个数。
Solution 1 - 位运算
如果一个整数不为 $0$,那么这个整数至少有一位是 $1$。如果我们把这个整数减 $1$,那么原来处在整数最右边的 $1$ 就会变为 $0$,原来在 $1$ 后面的所有的 $0$ 都会变成 $1$ (如果最右边的 $1$ 后面还有 $0$ 的话)。其余所有位将不会受到影响。
1 | n = 10101000 |
- 减 $1$ 的结果是把最右边的一个 $1$ 开始的所有位都取反了。
- 把一个整数减去 $1$ ,再和原整数做(与&)运算,会把该整数最右边一个 $1$ 变成 $0$。
- 那么一个整数的二进制有多少个 $1$,就可以进行多少次这样的操作。
1 | public int hammingWeight(int n) { |
- 时间复杂度:$O(n)$,最坏情况下 $n$ 的二进制表示中含有 $n$ 个 $1$。
- 空间复杂度: $O(1)$。
Solution 2 - 逐位与
逐位判断
- 根据 与运算 定义,设二进制数字 $n$ ,则有:
- 若 $n & 1 = 0$ ,则 $n$ 二进制位最右一位为 $0$;
- 若 $n & 1 = 1$ ,则 $n$ 二进制位最右一位为 $1$。
- 循环判断
- 若 $n$ 最右一位为 $1$ ,结果加 $1$;
- 将 $n$ 右移一位(本题要求把数字看作无符号数,因此采用无符号右移。)
1 | public int hammingWeight(int n) { |
- 时间复杂度:$O(\log_2 M)$,其中 $M$ 代表输入数字 $n$ 中最高位 $1$ 的位置,例如输入 $16$,则 $16_{10}=1111_2$,那么 $M = log_2 16 = 4$。
- 空间复杂度: $O(1)$。
Solution 3 - JDK
1 | public int hammingWeight(int n) { |
16. 数值的整数次方
题目描述
给定一个 $double$ 类型的浮点数 $base$ 和 $int$ 类型的整数 $exponent$。求 $base$ 的 $exponent$ 次方。保证 $base$ 和 $exponent$ 不同时为 $0$。不得使用库函数,同时不需要考虑大数问题。
Solution - 快速幂
二进制角度
设 $x=base, n=exponent$。
- 十进制整数 $n$ 可以表示为二进制的 $b_m\dots b_3b_2b_1$ ,则有
- 二进制转十进制: $n=1b_1+2b_2+4b_3+\cdots+2^{m-1}b_m$
- 幂的二进制展开: $x^n=x^{1b_1+2b_2+4b_3+\cdots + 2^{m-1}b_m}=x^{1b_1}x^{2b_2}x^{4b_3}\dots x^{2^{m-1}b_m}$
- 因此,根据以上操作,可在循环中计算 $x^{2^0b_1},x^{2^1b_2},\dots,x^{2^{m-1}b_m}$ 的值,并将所有 $x^{2^{i-1}b_i}$ 累积相乘即可。
- 当 $b_i=0$ 时, $x^{2{i-1}}b_i=1$。
- 当 $b_i=1$ 时, $x^{2{i-1}}b_i=x^{2^{i-1}}$。
二分角度
$$
x^n=
\begin{cases}
x^{\frac{n}{2}}·x^{\frac{n}{2}}, & n%2=0\
x·x^{\frac{n}{2}}·x^{\frac{n}{2}}, & n%2=1
\end{cases}
$$
- 幂结果获取
- 根据二分推导,可通过循环 $x=x^2$ 操作,每次把幂从 $n$ 降至 $n/2$ ,直至将幂降为 $0$ ;
- 设 $res = 1$ ,则初始状态 $x^n=x^n\times res$ 。在循环二分时,每当 $n$ 为奇数时,将多出的一项 $x$ 乘入 $res$ ,则最终可转化为 $x^n=x^0 \times res = res$。
- 转化为位运算
- 向下取整 $n/2$ 等价于右移一位 $n>>1$;
- 判断奇偶性操作 $n%2$ 等价于 $n&1$。
- 注意点:当 $n<0$ 时,把问题转化至 $n\ge 0$ 的范围内,即执行 $x=1/x,n=-n$。
1 | public double myPow(double x, int n) { |
- 时间复杂度:$O(\log_2n)$,二分的时间复杂度为对数级别。
- 时间复杂度:$O(1)$,有限个变量。
17. 打印从1到最大的n位数
题目描述
输入数字 $n$,按顺序打印出从 $1$ 到最大的 $n$ 位十进制数。比如输入 $3$,则打印出 $1、2、3$ 一直到最大的 $3$ 位数 $999$ 。
Solution-分治算法
根据题目要求,需要考虑两个问题:
- 最大的 $n$ 位数(记为 $end$ )和位数 $n$ 的关系:例如最大的 $1$ 位数是 $9$ ,最大的二位数是 $99$ ,因此可以得到:
$$
end = 10^n - 1
$$
- 大数越界问题:根据题意,不用考虑。
因此,只需要定义区间 $[1,10^n-1]$ 和步长 $1$,通过 $for$ 循环生成列表 $res$ 并返回即可。
实际上,本题的主要考点是大数越界情况下的打印。需要解决以下三个问题:
- 表示大数的数据类型:无论是
short/int/long及其他变量类型,数字的取值范围都是有限的。因此,大数的表示应用字符串String类型。 - 生成数字的字符串集:
- 使用
int类型时,每轮可通过+1生成下个数字,而此方法无法应用至String类型。并且,String类型的数字的进位操作效率较低,例如 “$9999$” 至 “$10000$” 需要从个位到千位循环判断,进位 $4$ 次。 - 观察可知,生成的列表实际上是 $n$ 位 $0\sim9$ 的 全排列 ,因此可避开进位操作,通过递归生成数字的
String列表。
- 使用
- 递归生成全排列:先固定高位,向低位递归,当个位已被固定时,添加数字的字符串。例如当 $n=2$ 时(数字范围 $1 \sim 99$ ),固定十位为 $0 \sim 9$ ,按顺序依次开启递归,固定个位 $0 \sim 9$ ,终止递归并添加数字字符串。
1 | class Solution { |
- 时间复杂度:$O(10^n)$,递归生成的排列数量为 $10^n$。
- 空间复杂度:$O(n)$,字符列表 $num$ 使用线性大小的额外空间。
18. 删除链表中的结点
题目描述
给定单向链表的头指针和一个要删除的结点的值,定义一个函数删除该结点。返回删除后的链表的头结点。
题目保证链表中节点的值互不相同。
1 | 输入: head = [4,5,1,9], val = 5 |
Solution - 双指针
删除值为 val 的节点可分为两步:定位节点、修改引用。
- 定位结点:遍历链表,直到找到
node.val == val时跳出,即可定位目标结点。 - 修改结点:设
cur指向当前结点,pre为cur的前驱结点,cur.next为cur的后继结点,则执行pre.next = cur.next,实现删除cur结点的功能。
算法流程
- 特例处理:当应删除头结点
head时,直接返回head.next即可。 - 初始化:
pre = head; cur = head.next; - 定位结点:当
cur为空,或者cur.val == val时跳出遍历。- 保存当前结点索引,执行
pre = cur; - 遍历下一结点,即
cur = cur.next。
- 保存当前结点索引,执行
- 删除结点:
- 若
cur指向某结点(即找到了与val值相等的结点),则执行pre.next = cur.next,实现删除结点的操作。 - 若
cur == null,代表链表中不包含val的结点。
- 若
- 返回值:返回头结点
head即可。
1 | public ListNode deleteNode(ListNode head, int val) { |
- 时间复杂度:$O(n)$,可能需要遍历整个链表搜索要删除的结点。
- 空间复杂度:$O(1)$,两个辅助结点。
19. 正则表达式匹配
请实现一个函数用来匹配包含 . 和 * 的正则表达式。模式中的字符 . 表示任意一个字符,而 * 表示它前面的字符可以出现任意次(含 $0$ 次)。在本题中,匹配是指字符串的所有字符匹配整个模式。例如,字符串 aaa 与模式 a.a 和 ab*ac*a 匹配,但与 aa.a 和 ab*a 均不匹配。
1 | 输入: |
s可能为空,且只包含从a-z的小写字母。p可能为空,且只包含从a-z的小写字母以及字符.和*,无连续的'*'。
Solution - 动态规划
感慨一下,自己现在终于能做出 DP 的题了。
关于为什么考虑动态规划?
- 经验:只要读题时思维乱成一团,八成就是动态规划。关于字符串的很多复杂问题也都要用到动态规划,典型的有:最长公共子序列、最长公共子串、最长上升子序列等。
- 理论:本题具有最优子结构性质,但是不容易发现。
- 通常拥有数学中递推性质的都可以用动态规划来解决。
题目中的匹配是一个「逐步匹配」的过程:我们每次从字符串 $p$ 中取出一个字符或者「字符 + *」的组合,并在 $s$ 中进行匹配。对于 $p$ 中一个字符而言,它只能在 $s$ 中匹配一个字符,匹配的方法具有唯一性;而对于$p$ 中「字符 + *」的组合而言,它可以在 $s$ 中匹配任意自然数个字符,并不具有唯一性。因此我们可以考虑使用动态规划,对匹配的方案进行枚举。
不少前辈说「动态规划」问题最难的地方在于「定义状态转移方程」,但是本题最困难的地方在于「定义状态」,也就是读懂题意。在诸如问「最大最小最多最少」的问题中一般问题最后要求的结果是什么,「状态定义」就是什么。
状态定义:$f[i][j]$ 表示 $s$ 的前 $i$ 个字符能否与 $p$ 中前 $j$ 个字符匹配。
状态转移:在一维 $DP$ 中, $dp[i]$ 通常与 $dp[i-1]$ 有关系,但条件限定的话也可能与 $dp[i-1]、dp[i-3]$ 有直接关系;在二维 $DP$ 中, $dp[i][j]$ 通常与 $dp[i-1][j]、dp[i][j-1]、dp[i-1][j-1]$ 有关系,如果条件限定的话,步长可能也会大一点;在三维及之后的问题,我想你已经明白我的意思了。
在高中数学中有种方法叫做归纳推理法,它的核心思想是假设 $n=k$ 时结论成立,那么 $n=k+1$ 时也成立,这是一种从前向后的方法,而寻找「状态转移方程」的过程可以简单理解为这个方法的逆过程,也就是从后向前的过程寻找状态,也就是我想要达到 $dp[i][j]$ 这个状态,我需要 $dp[i-1][j],dp[i][j-1],dp[i-1][j-1]$ 中的一种或多种状态满足什么样的条件。在计算「最大最小最多最少」问题时还可以想到高中排列组合中的「分步用乘法,分类用加法」这句话。
铺垫了这么多, $f[i][j]$ 与 $f[i-1][j],f[i][j-1],f[i-1][j-1]$ 建立关系时需要满足什么样的条件?
- 如果 $p$ 的第 $j$ 个字符是字母,那么想要匹配的话, $s$ 中的第 $i$ 个字母需要与其相同,即
$$
f[i][j]=
\begin{cases}
f[i-1][j-1], &s[i]=p[j] \
false,&s[i]\ne p[j]
\end{cases}
$$
- 如果 $p$ 的第 $j$ 个字符是「*」,那么可以使用 $p$ 的第 $j-1$ 个字母零次或多次。匹配零次时有
$$
f[i][j]=f[i][j-2]
$$
意思是,第 $j$ 位字符「*」没有用,第 $j-1$ 位又跟 $s$ 的第 $i$ 位不等,那就只能依靠 $p$ 的第 $i-2$ 位了。
在匹配多次时,有
$$
f[i][j]=
\begin{cases}
f[i][j]=f[i-1][j-2], \quad s[i]=p[j-1] \
f[i][j]=f[i-2][j-2], \quad s[i-1]=s[i]=p[j-1] \
f[i][j]=f[i-3][j-2], \quad s[i-1]=s[i-1]=s[i]=p[j-1] \
\dots
\end{cases}
$$
「字母 + *」的组合在匹配的过程中,本质上只会有两种情况:
- 匹配 $s$ 末尾的字符,将该字符丢弃之后,组合仍可以继续匹配;
- 不匹配字符,将该组合丢弃,不再进行匹配。
于是得到
$$
f[i][j]=
\begin{cases}
f[i-1][j]\ or\ f[i][j-2], & s[i]=p[j-1]\
f[i][j-2], & s[i]\ne p[j-1]
\end{cases}
$$
- 如果 $p$ 的第 $j$ 个字符是「
.」,那么 $p[j]$ 一定成功匹配 $s$ 中的任意一个小写字母。
三种情况下的状态转移方程合并
$$
f[i][j]=
\begin{cases}
if(p[j]\ne 「*」)=
\begin{cases}
f[i-1][j-1], &matches(s[i],p[j]) \
false, &otherwise
\end{cases} \
otherwise=
\begin{cases}
f[i-1][j]\ or\ f[i][j-2], &matches(s[i],p[j-1]) \
f[i][j-2], &otherwise
\end{cases}
\end{cases}
$$
其中,matches(a, b) 函数用于判断字符是否匹配。
状态初始化:$f[0][0]=true$,即两个空字符串是匹配的。
返回值:$f[m][n]$,其中 $m,\ n$ 分别问两个字符串的长度,这里 $dp$ 数组多开一行一列,但是不用。
1 | public boolean isMatch(String s, String p) { |
- 时间复杂度:$O(mn)$,需要计算出所有的状态,并且每个状态在进行转移时的时间复杂度为 $O(1)$。
- 空间复杂度:$O(mn)$,即为存储所有状态使用的空间。
20. 表示数值的字符串
请实现一个函数用来判断字符串是否表示数值(包括整数和小数)。例如,字符串”$+100$”、”$5e2$”、”$-123$”、”$3.1416$”、”$0123$”都表示数值,但”$12e$”、”$1a3.14$”、”$1.2.3$”、”$+-5$”都不是。
Solution-有限状态自动机
本题使用有限状态自动机。根据字符类型和合法数值的特点,先定义状态,再画出状态转移图,最后编写代码即可。
字符类型:空格「 」,数字「$0 \sim 9$」,正负号「$+-$」,小数点「$.$」幂符号「$e$」。
状态定义:按照字符串从左到右的顺序,定义以下 $9$ 种状态。
- 开始的空格
- 幂符号前的正负号
- 小数点前的数字
- 小数点、小数点后的数字
- 当小数点前为空格时,小数点、小数点后的数字
- 幂符号
- 幂符号后的正负号
- 幂符号后的数字
- 结尾的空格
合法的结束状态有:$2,3,7,8$。
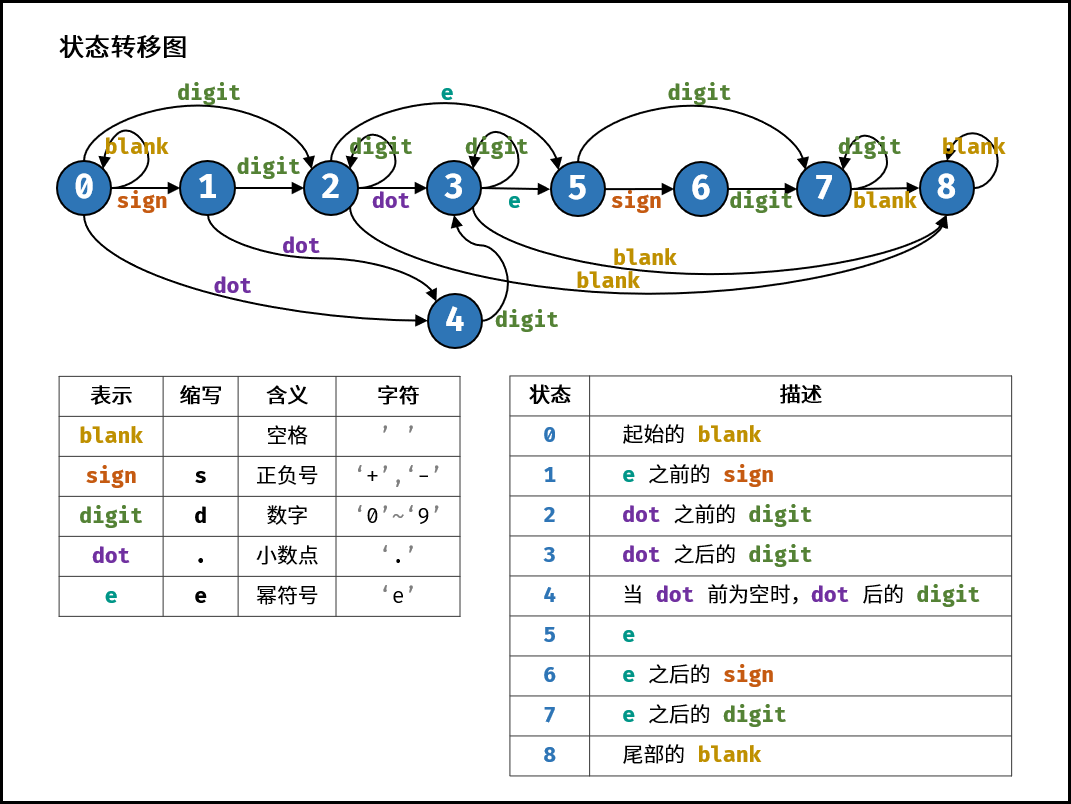
算法流程:
- 初始化:
- 状态转移表 $states$ ,设 $states[i]$ ,其中 $i$ 为所处状态, $states[i]$ 使用哈希表存储可转移至的状态。键值对 $(key,value)$ 含义:若输入 $key$ ,则可从状态 $i$ 转移至状态 $value$ 。
- 当前状态 $p$ :起始状态初始化为 $p=0$ 。
- 状态转移循环:遍历字符串 $s$ 的每个字符 $c$
- 记录字符类型 $t$ :分为三种情况
- 当 $c$ 为正负号时,
t = 's'; - 当 $c$ 为数字时,
t = 'd'; - 否则,
t = c,即用字符本身表示字符类。
- 当 $c$ 为正负号时,
- 终止条件:若字符类型 $t$ 不在哈希表 $states[p]$ 中,说明无法转移至下一状态,因此直接返回 $False$。
- 状态转移:状态 $p$ 转移至 $states[p][t]$。
- 记录字符类型 $t$ :分为三种情况
- 返回值:跳出循环后,若状态 $p \in 2,3,7,8$ ,说明结尾合法,返回 $True$ ,否则返回 $False$。
1 | class Solution { |
- 时间复杂度:$O(n)$,其中 $n$ 为字符串 $s$ 的长度,判断需遍历字符串,每轮状态转移使用 $O(1)$ 时间。
- 空间复杂度:$O(1)$, $states,p$ 使用常数大小的额外空间。
21. 调整数组顺序使奇数位于偶数前面
题目描述
输入一个整数数组,实现一个函数来调整该数组中数字的顺序,使得所有奇数位于数组的前半部分,所有偶数位于数组的后半部分。
1 | 输入:nums = [1,2,3,4] |
Solution 1 - 对撞指针
1 | public int[] exchange(int[] nums) { |
- 时间复杂度:$O(n)$,扫描一遍数组。
- 空间复杂度:$O(1)$,有限个变量。
Solution 2 : 快慢指针
1 | class Solution { |
- 时间复杂度:$O(n)$,扫描一遍数组。
- 空间复杂度:$O(1)$,有限个变量。
22. 链表中倒数第k个节点
题目描述
输入一个链表,输出该链表中倒数第 $k$ 个节点。为了符合大多数人的习惯,本题从 $1$ 开始计数,即链表的尾节点是倒数第 $1$ 个节点。例如,一个链表有 $6$ 个节点,从头节点开始,它们的值依次是 $1、2、3、4、5、6$。这个链表的倒数第 $3$ 个节点是值为 $4$ 的节点。
1 | 给定一个链表: 1->2->3->4->5, 和 k = 2. |
Solution-双指针
两个解题思路:
- 遍历链表一次,获取链表的长度 $n$ ,然后再遍历一次链表,但是这次只遍历到 $n-k$ 这个位置即可,此时即为链表的倒数第 $k$ 个结点。
- 使用双指针,让快的指针先走 $k$ 步,那么当快的指针到达到达链表尾部时,慢的指针正好到达倒数第 $k$ 个结点。
算法流程:
- 初始化:设快指针为
former,慢指针为latter,初始时都指向头结点head。 - 创建步差:让
former先走 $k$ 步。 - 同步前进:循环中,让
former和latter同步前进,直至former走过链表尾结点时跳出循环。 - 返回值:返回
latter。
1 | class Solution { |
- 时间复杂度:$O(n)$,遍历一次链表。
- 空间复杂度:$O(1)$。 两个辅助结点。
24. 反转链表
定义一个函数,输入一个链表的头节点,反转该链表并输出反转后链表的头节点。
1 | 反转一个单链表。 |
Solution 1 -双指针
算法流程:
- 初始化:定义两个指针,
cur指向当前结点,pre指针指向当前结点的下一个结点。 - 局部反转:每次让
pre.next指向cur。 - 同步移动:
pre和cur同步移动一个结点。 - 返回值:当
pre == null时,返回cur.
1 | public ListNode reverseList(ListNode head) { |
- 时间复杂度:$O(n)$,遍历一次链表。
- 空间复杂度:$O(1)$。 两个辅助结点。
Solution 2 - 递归
在实现逆序或者反转相关的操作时可以考虑使用“栈”这种数据结构,要么自己实现,要么调用系统栈,而提到系统栈,首先就要想到递归。递归可能不太好理解,这里有个幻灯片解释。
1 | public ListNode reverseList(ListNode head) { |
- 时间复杂度:$O(n)$,遍历一次链表,每次链接链表的操作为 $O(1)$。
- 空间复杂度:$O(n)$, 系统递归栈需要存储链表中的所有结点。
25. 合并两个已排序的链表
输入两个递增排序的链表,合并这两个链表并使新链表中的节点仍然是递增排序的。
Solution - 双指针
两个重要的隐含条件:有序、递增。
所以可以考虑使用双指针 $l_1,l_2$ 分别遍历两链表,根据 $l_1.val,l_2.val$ 的大小关系来确定结点添加顺序,两结点指针交替前进,直至遍历完毕。
由于初始状态合并链表中无结点,所以需要设置一个头结点。
算法流程:
- 初始化:创建伪头结点 $dummy$,结点 $cur$ 指向 $dummy$。
- 循环合并:当 $l_1$ 或 $l_2$ 为空时跳出。
- 当 $l_1.val < l_2.val$ 时: $cur$ 的后继结点指定为 $l1$ , $l_1$ 向前走一步;
- 当 $l_1.val \ge l_2.val$ 时: $cur$ 的后继结点指定为 $l2$ , $l_2$ 向前走一步;
- 结点 $cur$ 向前走一步,即 $cur = cur.next$。
- 合并剩余尾部:跳出时有两种情况,即 $l_1$ 为空或 $l_2$ 为空。
- 若 $l_1\ne null$ ,将 $l_1$ 添加至结点 $cur$ 结点之后;
- 否则,将 $l_2$ 添加至结点 $cur$ 之后。
1 | class Solution { |
- 时间复杂度:$O(m+n)$,需要遍历两个链表。
- 空间复杂度:$O(1)$,两个辅助结点。
26(🌲). 树的子结构
题目描述
输入两棵二叉树 $A$ 和 $B$ ,判断 $B$ 是不是 $A$ 的子结构。(约定空树不是任意一个树的子结构)。
$B$ 是 $A$ 的子结构, 即 $A$ 中有出现和 $B$ 相同的结构和节点值。
Solution - 先序遍历
若树 $B$ 是树 $A$ 的子结构,则子结构的根节点可能为树 $A$ 的任意一个节点。因此,判断树 $B$ 是否是树 的子结 $A$ 构,需完成以下两步工作:
- 先序遍历 $A$ 的每个节点 $n_A$ ,
isSubStructure(A, B) - 判断树 $A$ 中以 $n_A$ 为根节点的子树是否包含树 $B$ ,
recur(A, B)
名词规定:树 $A$ 的根节点记作 节点 $A$ ,树 $B$ 的根节点称为节点 $B$ 。
recur(A, B)函数:
- 终止条件:
- 当结点 $B$ 为空:说明树 $B$ 已匹配完成,返回 $true$
- 当结点 $A$ 为空:说明已经越过树 $A$ 叶子结点,即匹配失败,返回 $false$
- 当结点 $A、B$ 的值不同:说明匹配失败,返回 $false$
- 返回值:
- 判断 $A$ 和 $B$ 的左子结点是否相等,即
recur(A.left, B.left) - 判断 $A$ 和 $B$ 的右子结点是否相等,即
recur(A.right, B.right)
- 判断 $A$ 和 $B$ 的左子结点是否相等,即
isSubstructure(A, B)函数:
- 特例处理:当树 $A$ 为空或树 $B$ 为空时,直接返回 $false$。
- 返回值:若树 $B$ 是树 $A$ 的子结构,则必须满足以下三种情况之一,因此可用或
||连接。- 以 节点 $A$ 为根节点的子树 包含树 $B$ ,对应
recur(A, B); - 树 $B$ 是 树 $A$ 左子树 的子结构,对应
isSubStructure(A.left, B); - 树 $B$ 是 树 $A$ 右子树 的子结构,对应
isSubStructure(A.right, B)。1
2
3
4
5
6
7
8
9
10
11
12
13
14public boolean isSubStructure(TreeNode A, TreeNode B) {
// 只有在 A B 均不为空时才有可能出现子结构
// 1. 以 A 为根结点的子树包含 B recur(A, B)
// 2. 以 A 的左结点为根结点的子树包含 B isSubStructure(A.left, B)
// 3. 以 A 的右结点为根结点的子树包含 B isSubStructure(A.right, B)
return (A != null && B != null) || (recur(A, B) || isSubStructure(A.left, B) || isSubStructure(A.right, B));
}
public boolean recur(TreeNode A, TreeNode B) {
if (B == null) return true; // 如果 B 的子树为空 说明已经到达了B的叶子结点,也就是说整个树B都包含在了A中
if (A == null || A.val != B.val) return false; // 如果 A 的子树为空,说明已经到达了A的叶子结点,不会再有子树
// 继续判断 A B 的左右子结点是否相同
return recur(A.left, B.left) && recur(A.right, B.right);
}
- 以 节点 $A$ 为根节点的子树 包含树 $B$ ,对应
- 时间复杂度:$O(MN)$,其中 $M,N$ 分别为两树种结点的数量。
- 空间复杂度:$O(M)$,当$A、B$ 都退化为链表时,递归调用深度最大。
27(🌲).二叉树的镜像
题目描述
请完成一个函数,输入一个二叉树,该函数输出它的镜像。
1 | 输入: |
Solution 1 - 递归
递归遍历二叉树,交换每个节点的 左/右 子节点,即可生成二叉树的镜像。
递归解析
- 终止条件:当节点 $root$ 为空时返回 $null$ ;
- 递推工作:
- 初始化节点 $tmp$,用于暂存 $root$ 的左子节点;
- 递归右子节点,将返回值作为 $root$ 的左子节点;
- 递归左子节点,将返回值作为 $root$ 的右子节点。
- 返回值:返回 $root$。
Question: 为何要暂存 $root$ 左子节点?
Answer:在递归右子节点完毕后,$root.left$ 的值已发生改变。
1 | public TreeNode mirrorTree(TreeNode root) { |
- 时间复杂度:$O(n)$,其中 $n$ 为二叉树的节点数量,建立二叉树镜像需要遍历树的所有节点,占用 $O(n)$ 时间。
- 空间复杂度: $O(n)$ ,最差情况下(当二叉树退化为链表),递归时系统需使用 $O(n)$ 大小的栈空间。
扩展:
- 本题竟是 $Homebrew$ 之父当年没能写出的 226. 翻转二叉树
- 前序、中序、后序、层次遍历解本题
Solution 2 - 辅助栈
利用栈(或队列)遍历树的所有节点 $node$ ,并交换每个 $node$ 的左 / 右子节点。
1 | public TreeNode mirrorTree(TreeNode root) { |
- 时间复杂度: $O(n)$ ,其中 $n$ 为二叉树的节点数量,建立二叉树镜像需要遍历树的所有节点,占用 $O(n)$ 时间。
- 空间复杂度: $O(n)$ ,最差情况下(当为满二叉树时),栈 $stack$ 最多同时存储 $n/2$ 个节点,占用 $O(n)$ 额外空间。
28(🌲). 对称的二叉树
题目描述
实现一个函数,用来判断一棵二叉树是不是对称的。如果一棵二叉树和它的镜像一样,那么它是对称的。
例如,二叉树 $[1,2,2,3,4,4,3]$ 是对称的。
1 | 1 |
Solution - 递归
大部分人看到本题时应该都已经有思路了,本题最大的问题其实并不是思路的问题,而是是否有能力把思路表达出来的问题。
除去递归终止条件,要判断的主要有三点,
- 两个指针指向的节点的 $val$ 是否相等;
- $L$ 的左子树是否与 $R$ 的右子树对称;
- $L$ 的右子树是否与 $R$ 的左子树对称。
递归终止条件:
- 两个指针都为 $null$ 则返回 $true$ ;
- 两个指针其中之一为 $null$ 则返回 $false$ 。
1 | public boolean isSymmetric(TreeNode root) { |
- 时间复杂度:$O(n)$,$n$ 为节点数量,每次递归可以判断一对节点是否对称,最多执行 $n/2$ 次;
- 空间复杂度:$O(n)$,二叉树退化为链表时系统使用 $O(n)$ 栈空间。
29. 顺时针打印矩阵
题目描述
输入一个矩阵,按照从外向里以顺时针的顺序依次打印出每一个数字。
1 | 输入:matrix = [[1,2,3],[4,5,6],[7,8,9]] |
Solution - 收缩
逆时针打印矩阵,也可以理解为打印顺序为:从左向右,自上而下,从右向左,自下而上。因此考虑设置矩阵的上、下、左、右四个边界,模拟矩阵收缩。
算法流程:
- 空值处理:当
matrix为空时,直接返回空列表。 - 初始化:设置上下左右四边界,
top,bottom,left,right,用于矩阵向内收缩。 - 循环打印:按”从左向右,自上而下,从右向左,自下而上”的方式循环,每个方向打印的过程中包括以下三件事:
- 根据边界打印,将结果存储到
res中尾部; - 边界向内收缩 $1$;
- 判断边界是否相遇,若相遇则跳出。
- 根据边界打印,将结果存储到
- 返回值:返回结果
res。
1 | public int[] spiralOrder(int[][] matrix) { |
- 时间复杂度:$O(MN)$,其中 $M,N$ 分别为矩阵行列。
- 空间复杂度:$O(1)$,四个方向值。
30. 包含min函数的栈
定义栈的数据结构,请在该类型中实现一个能够得到栈的最小元素的 $min$ 函数在该栈中,调用 $min,push$ 及 $pop$ 的时间复杂度都是 $O(1)$。
1 | MinStack minStack = new MinStack(); |
Solution-辅助栈
将 min() 函数复杂度降为 $O(1)$ ,可通过建立辅助栈实现
- 数据栈
stackData: 用于存储所有元素,保证入栈push()、pop()、top()等功能。 - 辅助栈
stackHelper: 用于以非严格降序存储stackData中的数据,stackHelper的栈顶元素始终为stackData中的最小元素,返回stackHelper的栈顶元素,即可实现min()函数的功能。
在操作的过程中为了保证 stackData 的非严格单调性,需要注意:
- 在
push()操作时,设待push的元素为e,如果stackHelper为空或者e <= stackHelper.peek(),那么将e也push到stackHelper中; - 在
pop()操作时,设待pop()的元素为e,如果e == stackHelper.peek(),那么从stackHelper也进行pop()。
1 | public class MinStack { |
- 时间复杂度:$O(1)$,不必多言。
- 空间复杂度:$O(n)$,最坏情况下,比如输入一个单调递减的数列,那么
stackHelper将需要存储所有元素。
31. 栈的压入、弹出序列
题目描述
输入两个整数序列,第一个序列表示栈的压入顺序,请判断第二个序列是否为该栈的弹出顺序。假设压入栈的所有数字均不相等。例如,序列 ${1,2,3,4,5}$ 是某栈的压栈序列,序列 ${4,5,3,2,1}$ 是该压栈序列对应的一个弹出序列,但 ${4,3,5,1,2}$ 就不可能是该压栈序列的弹出序列。
1 | 输入:pushed = [1,2,3,4,5], popped = [4,5,3,2,1] |
Solution
因为栈的数据操作具有 先入后出 的特性,因此某些弹出序列是无法实现的。考虑借用一个辅助栈 $stack$ ,模拟 压入 / 弹出操作的排列。根据是否模拟成功,即可得到结果。
- 入栈操作:按照压栈序列的顺序执行;
- 出栈操作:每次入栈后,循环判断“栈顶元素=弹出序列的当前元素”是否成立,降负荷弹出序列顺序的栈顶元素全部弹出。
算法流程:
- 初始化:辅助栈 $stack$ ,弹出序列的索引 $i$。
- 遍历压栈序列:设各元素为 $num$
- $num$ 入栈;
- 循环出栈:若 $stack$ 的栈顶元素=弹出序列元素 $popped[i]$ ,则执行出栈与
i++。
- 返回值:若 $stack$ 为空,则此弹出序列合法。
1 | public boolean validateStackSequences(int[] pushed, int[] popped) { |
- 时间复杂度 $O(N)$ : 其中 $N$ 为列表 $pushed$ 的长度;每个元素最多入栈与出栈一次,即最多共 $2N$ 次出入栈操作。
- 空间复杂度 $O(N)$ : 辅助栈 $stack$ 最多同时存储 $N$ 个元素。
32(🌲). 从上到下打印二叉树 I
题目描述
从上到下打印出二叉树的每个节点,同一层的节点按照从左到右的顺序打印。
1 | 给定二叉树: [3,9,20,null,null,15,7] |
Solution - 层次遍历
树的遍历除了前序遍历、中序遍历、后序遍历之外,还有层次遍历,题目描述其实就是对层次遍历的解释。
在层次遍历中使用 $BFS$ 需要用到队列,在 $DFS$ 中往往需要用到栈。
算法流程
- 特例处理:当树的根节点为空,则直接返回空列表
[]; - 初始化:打印结果列表
res = [],包含根节点的队列queue = [root]; - $BFS$ 循环:当队列
queue为空时跳出;- 出队:队首元素出队,记为
node; - 打印:将
node.val添加至列表tmp尾部; - 添加子节点: 若
node的左(右)子节点不为空,则将左(右)子节点加入队列queue。
- 出队:队首元素出队,记为
- 返回值:返回
res即可。
1 | public int[] levelOrder(TreeNode root) { |
- 时间复杂度 $O(n)$ : $n$ 为二叉树的节点数量,即 $BFS$ 需循环 $n$ 次。
- 空间复杂度 $O(n)$ : 最差情况下,即当树为满二叉树时,最多有 $n/2$ 个树节点同时在 $queue$ 中,使用 $O(n)$ 大小的额外空间。
32(🌲). 从上到下打印二叉树 II
题目描述
从上到下按层打印二叉树,同一层的节点按从左到右的顺序打印,每一层打印到一行。
1 | 给定二叉树: [3,9,20,null,null,15,7] |
Solution - 层次遍历
本题解法与上题几乎完全相同,唯一的不同点在与 $BFS$ 循环中对每层结点进行分层。
算法流程
- 特例处理:当树的根节点为空,则直接返回空列表
[]; - 初始化:打印结果列表
res = [],包含根节点的队列queue = [root]; - $BFS$ 循环:当队列
queue为空时跳出;- 申请一个用于存储当前层节点的临时列表
tmp; - 当前层打印循环:循环次数为
queue.size()- 出队:队首元素出队,记为
node; - 打印:将
node.val添加至列表tmp尾部; - 添加子节点: 若
node的左(右)子节点不为空,则将左(右)子节点加入队列queue;
- 出队:队首元素出队,记为
- 申请一个用于存储当前层节点的临时列表
- 返回值:返回
res即可。
1 | public List<List<Integer>> levelOrder(TreeNode root) { |
- 时间复杂度 $O(n)$ : $n$ 为二叉树的节点数量,即 $BFS$ 需循环 $n$ 次。
- 空间复杂度 $O(n)$ : 最差情况下,即当树为时满,最多有 $n/2$ 个树节点同时在 $queue$ 中,使用 $O(n)$ 大小的额外空间。
32(🌲). 从上到下打印二叉树 III
题目描述
请实现一个函数按照之字形顺序打印二叉树,即第一行按照从左到右的顺序打印,第二层按照从右到左的顺序打印,第三行再按照从左到右的顺序打印,其他行以此类推。
1 | 给定二叉树: [3,9,20,null,null,15,7] |
Solution - 层次遍历
本题又在上一题的基础上增加了条件 - $Z$ 字型打印,所以我们需要做的就是控制方向。双向链表正好可以完成这项工作,也就是:
- 在奇数层,将当前层的节点添加到链表尾部;
- 在偶数层,将当前层的节点添加到链表头部。
算法流程
- 特例处理:当树的根节点为空,则直接返回空列表
[]; - 初始化:打印结果列表
res = [],包含根节点的队列queue = [root]; - $BFS$ 循环:当队列
queue为空时跳出;- 申请一个用于存储当前层节点的临时列表
tmp; - 当前层打印循环:循环次数为
queue.size()- 出队:队首元素出队,记为
node; - 打印:若为奇数层,将
node.val添加至列表tmp尾部;否则添加至头部; - 添加子节点: 若
node的左(右)子节点不为空,则将左(右)子节点加入队列queue。
- 出队:队首元素出队,记为
- 申请一个用于存储当前层节点的临时列表
- 返回值:返回
res即可。
1 | public List<List<Integer>> levelOrder(TreeNode root) { |
- 时间复杂度 $O(n)$ : $n$ 为二叉树的节点数量,即 $BFS$ 需循环 $n$ 次。
- 空间复杂度 $O(n)$ : 最差情况下,即当树为满二叉树时,最多有 $n/2$ 个树节点同时在 $queue$ 中,使用 $O(n)$ 大小的额外空间。
33(🌲). 二叉搜索树的后序遍历序列
题目描述
输入一个整数数组,判断该数组是不是某二叉搜索树的后序遍历结果。如果是则返回 true,否则返回 false。假设输入的数组的任意两个数字都互不相同。
参考以下这颗二叉搜索树:
1 | 5 |
Solution 1 - 分治
- 后序遍历定义:
[ 左子树 | 右子树 | 根节点 ],即遍历顺序为 “左、右、根” 。 - 二叉搜索树定义: 左子树中所有节点的值 $<$ 根节点的值;右子树中所有节点的值 $>$ 根节点的值;其左、右子树也分别为二叉搜索树。

根据二叉搜索树的定义,可以通过递归,判断所有子树的 正确性 (即其后序遍历是否满足二叉搜索树的定义) ,若所有子树都正确,则此序列为二叉搜索树的后序遍历。
算法流程
- 终止条件:$i > j$,说明此子树数量 $\le 1$,无需判断正确性,直接返回 $true$;
- 递推工作:
- 划分左右子树:遍历后序遍历的 $[i,j]$ 区间元素,寻找第一个大于根节点的节点,索引记为 $m$ 。此时,可划分出左子树区间 $[i, m-1]$ ,右子树区间 $[m, j-1]$ ,根节点索引 $j$ ;
- 判断是否为二叉搜索树:
- 左子树区间 $[i, m - 1]$ 内的所有节点都应 $< postorder[j]$ 。而第
1.划分左右子树步骤已经保证左子树区间的正确性,因此只需要判断右子树区间即可。 - 右子树区间 $[m, j-1]$ 内的所有节点都应 $> postorder[j]$。实现方式为遍历,当遇到 $\leq postorder[j]$ 的节点则跳出;则可通过 $p = j$ 判断是否为二叉搜索树。
- 左子树区间 $[i, m - 1]$ 内的所有节点都应 $< postorder[j]$ 。而第
- 返回值: 所有子树都需正确才可判定正确,因此使用 与逻辑符 $&&$ 连接。
- $p = j$ : 判断 此树 是否正确;
- $recur(i, m - 1)$: 判断 此树的左子树 是否正确;
- $recur(m, j - 1)$: 判断 此树的右子树 是否正确。
下为动图,建议到大佬博客观看,效果更佳。

1 | public boolean verifyPostorder(int[] postorder) { |
- 时间复杂度:$O(n^2)$,每次调用 $recur(i,j)$ 减去一个根节点,因此递归占用 $O(n)$;最差情况下(即当树退化为链表),每轮递归都需遍历树所有节点,占用 $O(n)$ 。
- 空间复杂度:$O(n)$,最差情况下(即当树退化为链表),递归深度将达到 $n$。
Solution 2 - 单调栈
点击链接自行前往
34(🌲). 二叉树中和为某一值的路径
题目描述
输入一棵二叉树和一个整数,打印出二叉树中节点值的和为输入整数的所有路径。从树的根节点开始往下一直到叶节点所经过的节点形成一条路径。
给定如下二叉树,以及目标和 $sum = 22$。
1 | 5 |
Solution - 回溯
本问题是典型的二叉树方案搜索问题,使用回溯法解决,其包含 先序遍历 + 路径记录 两部分。
- 先序遍历: 按照“根、左、右”的顺序,遍历树的所有节点。
- 路径记录: 在先序遍历中,当 ① 根节点到叶节点形成的路径 且 ② 路径各节点值的和等于目标值
sum时,记录此路径。

算法流程
pathSum(root, sum) 函数:
- 初始化: 结果列表
res,路径列表path。 - 返回值: 返回
res即可。
recur(root, tar) 函数:
- 递推参数: 当前节点
root,当前目标值tar。 - 终止条件: 若节点
root为空,则直接返回。 - 递推工作:
- 路径更新: 将当前节点值
root.val加入路径path; - 目标值更新:
tar = tar - root.val(即目标值tar从sum减至 $0$ ); - 路径记录: 当 ①
root的左 / 右子节点都为空(即root为叶节点) 且 ②tar等于 $0$ (即路径和等于目标值),则将此路径path加入res。 - 先序遍历: 递归左 / 右子节点。
- 路径恢复: 向上回溯前,需要将当前节点从路径
path中删除,即执行path.pop()。
- 路径更新: 将当前节点值

$NOTE:$ 记录路径时若直接执行
res.append(path),则是将path对象加入了res;后续path改变时,res中的path对象也会随之改变。正确做法:
res.append(list(path)),相当于复制了一个path并加入到res。
1 | public class Solution { |
- 时间复杂度 $O(n)$ : $n$ 为二叉树的节点数,先序遍历需要遍历所有节点。
- 时间复杂度 $O(n)$ : 最差情况下,即树退化为链表时,$path$ 存储所有树节点,使用 $O(n)$ 额外空间。
35. 复杂链表的复制
题目描述
请实现 copyRandomList 函数,复制一个复杂链表。在复杂链表中,每个节点除了有一个 $next$ 指针指向下一个节点,还有一个 $random$ 指针指向链表中的任意节点或者 $null$。

Solution 1 - 哈希表
1 | public Node copyRandomList(Node head) { |
- 时间复杂度:$O(n)$。
- 空间复杂度:$O(n)$。
Solution 2 - DFS
题解:腐烂的橘子
本题的意思是复制一个链表并返回,这个链表与一般链表不同的是多了一个 $random$ 指针。
在这里,复制的意思是指 深拷贝(Deep Copy),类似我们常用的“复制粘贴”。
本题链表可以以图的形式来表示,因为图的遍历方式有 $DFS、BFS$ 两种,所以对于此链表而言, $DFS、BFS$ 也应该可行。
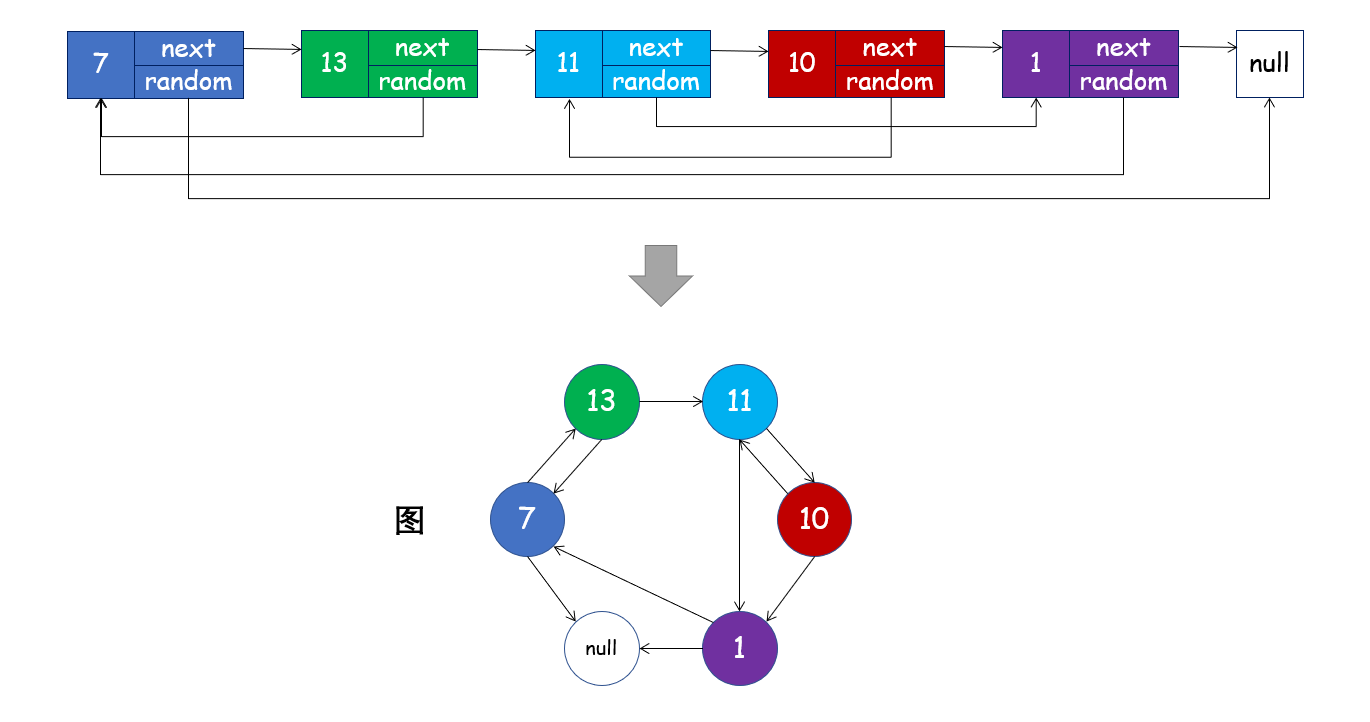
深度优先搜索 DFS
- 从头结点 $head$ 开始拷贝;
- 由于一个结点可能被多个指针所指向,因此如果该结点已被拷贝,则不需要重复拷贝;
- 如果还未拷贝当前结点,则创建一个新的结点进行拷贝,并将拷贝过的结点保存在哈希表中;
- 使用递归拷贝所有的 $next$ 结点,再递归拷贝所有的 $random$ 结点。
1 | class Solution: |
- 时间复杂度:$O(n)$。
- 空间复杂度:$O(n)$。
36(🌲). 二叉搜索树与双向链表
题目描述
输入一棵二叉搜索树,将该二叉搜索树转换成一个排序的循环双向链表。要求不能创建任何新的节点,只能调整树中节点指针的指向。
比如下面这棵树
1 | 4 |
将这棵二叉搜索树转化为双向循环链表。链表中的每个结点都有一个前驱和后继指针。对于双向循环链表,第一个结点的前驱是最后一个结点,最后一个结点的后继是第一个结点。
下图展示了上面的二叉搜索树转化成的链表。$head$ 表示指向链表中有最小元素的。
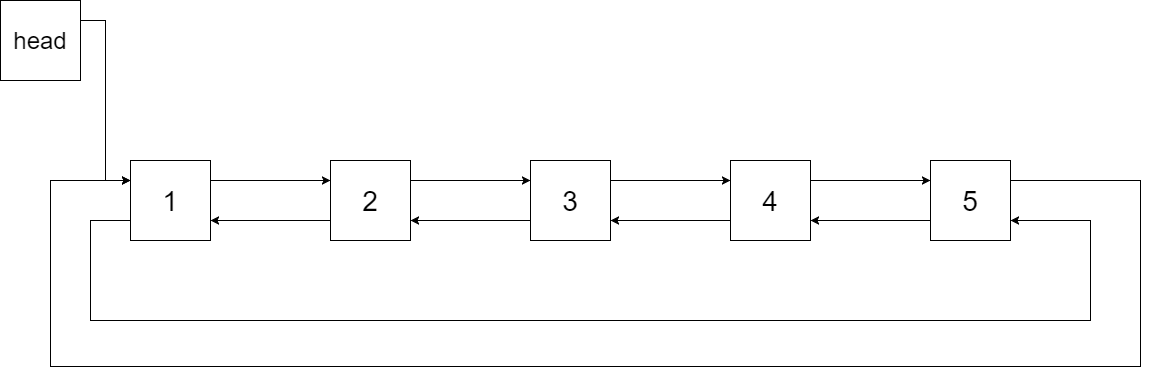
特别地,我们希望可以就地完成转换操作。当转化完成以后,树中节点的左指针需要指向前驱,树中节点的右指针需要指向后继。还需要返回链表中的第一个结点的指针。
Solution - 中序遍历
二叉搜索树的中序遍历为 递增序列。
将二叉搜索树转换成一个 “排序的循环双向链表” ,其中包含三个要素:
- 排序链表: 节点应从小到大排序,因此应使用 中序遍历 “从小到大”访问树的节点;
- 双向链表: 在构建相邻节点(设前驱节点 $pre$ ,当前节点 $cur$ )关系时,需要同时满足 $pre.right=cur $ 与 $cur.left=pre$ ;
- 循环链表: 设链表头结点 $head$ 和尾结点 $tail$,则应当构建 $head.left = tail$ 与 $tail.right=head$ 。
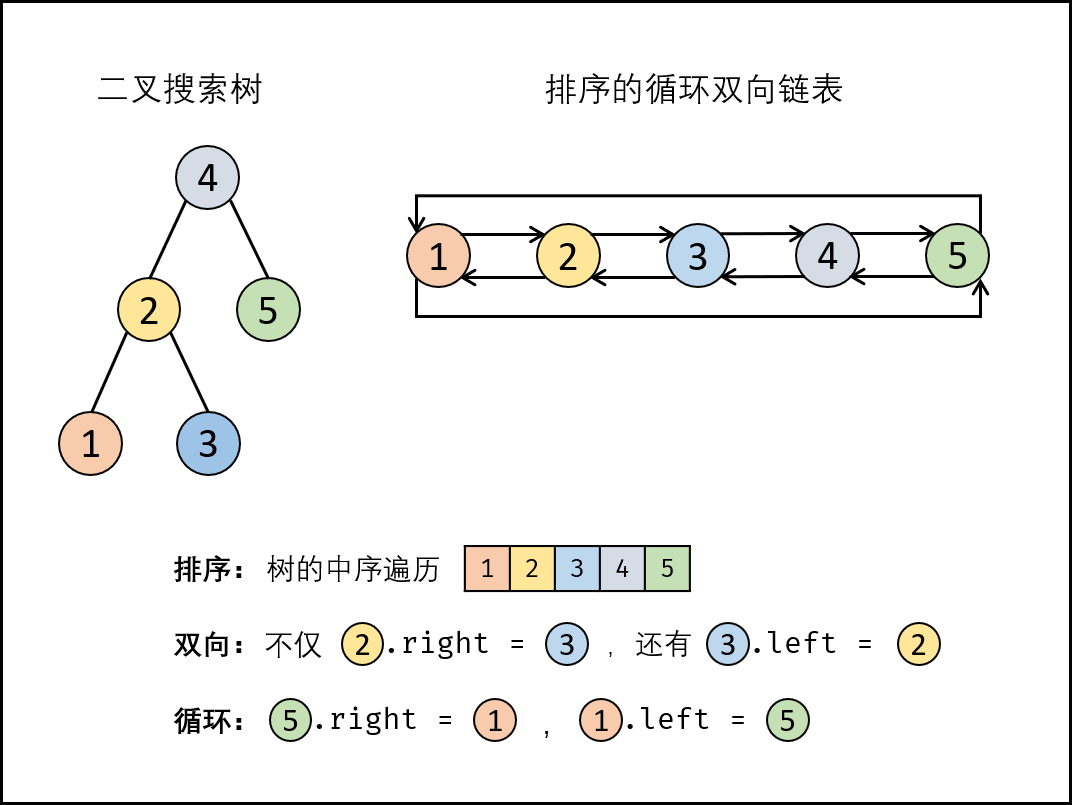
经过以上分析之后,选择使用中序遍历访问树中各节点,并在访问每个节点时构建 $cur$ 和前驱节点 $pre$ 的引用;待到中序遍历结束时,构建首尾节点的引用指向。
算法流程
dfs(cur): 递归法中序遍历;
- 终止条件: 当节点 $cur$ 为空,代表越过叶节点,直接返回。
- 递归左子树:即
dfs(cur.left)。 - 构建链表:
- 当
pre为空时:代表正在访问链表头结点,记为head; - 当
pre不为空时:修改双向结点引用,即pre.right = cur;,cur.left = pre; - 保存
cur:更新pre = cur,即结点cur是后继结点的pre。
- 当
- 递归右子树,即
dfs(cur.left)。
treeToDoublyList(root)
- 特例处理:若节点
root为空,则直接返回; - 初始化:空节点
pre; - 转化为双向链表:调用
dfs(root); - 构建循环链表:中序遍历完成后,
head指向头节点,pre指向尾节点,因此修改head和pre的双向节点引用即可。 - 返回值: 返回链表的头节点
head即可。
1 | public class Solution { |
- 时间复杂度:$O(n)$,$n$ 为二叉树的节点个数,中序遍历需要访问所有节点。
- 空间复杂度:$O(n)$,最差情况下,即树退化为链表时,递归深度达到 $n$。
37(🌲). 序列化二叉树
题目描述
序列化是将一个数据结构或者对象转换为连续的比特位的操作,进而可以将转换后的数据存储在一个文件或者内存中,同时也可以通过网络传输到另一个计算机环境,采取相反方式重构得到原数据。
请实现两个函数,分别用来序列化和反序列化二叉树。
1 | 你可以将以下二叉树: |
Solution - 先序遍历
要序列化二叉树,其实就是需要选用一种编码方式对其进行编码,类似的,反序列化就是使用同样的编码方式进行逆操作,进行解码。
我们可以边遍历树边对其进行编码,树的遍历方式可以分为 $BFS$ 与 $DFS$,其中 $BFS$ 就是层序遍历;而 $DFS$ 包括前序、中序、后序三种遍历方式。在此选择前序遍历的方式。
serialize(TreeNode root)
- 初始化:初始化结果
res = ""; - 算法流程:从根节点开始遍历,根据遍历到的节点是否为空来决定向
res中拼接的字符串。- 如果当前结点不为空,则将其值拼接到
res后; - 如果当前结点为空,则将
null拼接到res后。
- 如果当前结点不为空,则将其值拼接到
- 返回值:返回
res。
deserialize(String data)
- 把
data进行分割,然后遍历分割得到的元素列表。 - 如果当前元素为
null,则当前子树为空树; - 否则按照 先序遍历 的方式先解析这棵树的左子树,然后再解析它的右子树。
1 | public class Codec { |
- 时间复杂度:其中 $n$ 为节点的个数。在序列化与反序列化过程中,访问且仅访问每个节点一次。所以时间复杂度 $O(n)$。
- 空间复杂度:在序列化与反序列化过程总,递归栈最多达到 $O(n)$。
38. 字符串的排列
题目描述
输入一个字符串,打印出该字符串中字符的所有排列。
可以以任意顺序返回这个字符串数组,但里面不能有重复元素。
1 | 输入:s = "abc" |
Solution - 回溯
排列的数量:对于一个长度为 $n$ 的字符串(假设字符各不相同),其排列共有 $n!$ 种。
排列的生成方法:根据字符串排列的特点,考虑深度优先搜索所有排列方案。即通过字符交换,先固定 $1$ 位字符( $n$ 种情况)、再固定第 $2$ 位字符( $n-1$ 种情况)、 $\dots$ 、最后固定第 $n$ 位字符( $1$ 种情况)。
重复方案与剪枝:当字符串存在重复字符时,排列方案中也存在重复方案,为排除重复方案,需在固定某位字符时保证“每种字符在此位只固定一次”,即遇到重复字符时不交换,直接跳过。
递归解析
- 终止条件:当 $x=len(c)-1$ 时,代表所有位以固定(最后一位只有 $1$ 种情况),则将当前组合 $c$ 转化为字符串并加入 $res$ ,并返回。
- 递推参数:当前固定位 $x$ 。
- 递推工作:初始化一个 $Set$ ,用于排除重复的字符;将第 $x$ 位字符与 $i\in [x, len(c)]$ 字符分别交换,并进入下层递归。
- 剪枝:若 $c[i]$ 在 $Set$ 中,代表其实重复字符,因此剪枝;
- 将 $c[i]$ 加入 $Set$ ,以便之后遇到重复字符时剪枝;
- 固定字符:将字符 $c[i]$ 和 $c[x]$ 交换,即固定 $c[i]$ 为当前位字符;
- 开启下层递归:调用 $dfs(x+1)$ ,即开始第 $x+1$ 个字符;
- 还原交换:将字符 $c[i]$ 和 $c[x]$ 交换(还原之前的交换)。
1 | public class Solution { |
- 时间复杂度: $O(N!)$ , $N$ 为字符串的长度,时间复杂度和字符串排列的方案成线性关系,方案数为 $N!$ ,因此复杂度为 $O(N!)$。
- 空间复杂度: $O(N^2)$ ,全排列的递归深度为 $N$ ,系统累积使用栈空间大小为 $O(N)$ ,递归中辅助 $Set$ 累计存储的字符数量为 $N+(N-1)+\dots+2+1$ ,即占用 $O(N^2)$ 的额外空间。
拓展解析
39. 数组中出现次数超过一半的数字
1 | 数组中有一个数字出现的次数超过数组长度的一半,请找出这个数字。你可以假设数组是非空的,并且给定的数组总是存在多数元素。 |
Solution 1 - 快排
既然数组中总是存在多数元素,那么多数元素一定至少占了数组的 $1/2$ ,那么数组中间的位置一定是多数元素。
其实只要对数组进行排序即可,但是一般情况下快排的效率最高,所以选择快排。
1 | public int majorityElement(int[] nums) { |
- 时间复杂度:$O(n\lg n)$,快排的时间复杂度。
- 时间复杂度:$O(\lg n)$,快排使用分治递归,但是我也没有详细看过 $JDK$ 快排的实现。
Solution 2 - 摩尔投票法
摩尔投票法:
- 票数和: 由于众数出现的次数超过数组长度的一半;若记 众数 的票数为 $+1$ ,非众数 的票数为 $−1$ ,则一定有所有数字的 票数和 $> 0$ 。
- 票数正负抵消: 设数组 $nums$ 中的众数为 $x$ ,数组长度为 $n$ 。若 $nums$ 的前 $a$ 个数字的 票数和 $=0$ ,则 数组后 $(n−a)$ 个数字的 票数和一定仍 $>0$ (即后 $(n-a)$ 个数字的 众数仍为 $x$ )。
算法原理:
- 为构建正负抵消,假设数组首个元素 $n_1$ 为众数,遍历统计票数,当发生正负抵消时,剩余数组的众数一定不变 ,设真正的众数为 $x$
- 当 $n_1 = x$:抵消的所有数字中,有一半是众数。
- 当 $n_1 \ne x$:抵消的所有数字中,少于或等于一半是众数。
算法流程:
- 初始化:票数统计 $votes$ ,众数 $majority$。
- 循环抵消:遍历数组 $nums$ 中的每个元素 $num$
- 如果当前票数等于 $0$,那么假设当前数字 $num$ 为众数 $x$;
- 当 $num = x$ 时,票数
votes++,否则,票数votes--。
- 返回值:返回众数 $x$ 即可。
1 | public int majorityElement(int[] nums) { |
- 时间复杂度:$O(n)$, $n$ 为数组长度。
- 时间复杂度:$O(1)$,两个变量。
40. 最小的 k 个数
题目描述
输入整数数组 $arr$ ,找出其中最小的 $k$ 个数。例如,输入 $4、5、1、6、2、7、3、8$ 这 $8$ 个数字,则最小的 $4$ 个数字是 $1、2、3、4$。
1 | 输入:arr = [3,2,1], k = 2 |
Solution - 快速选择
先对数组进行排序,如果是非递减序的话,那么前 $k$ 个元素则为最小的 $k$ 个数。
快速排序的 $partition()$ 方法,会返回一个整数 j 使得 $a[l..j-1] \le a[j]$,且 $a[j+1..h] \ge a[j]$,此时 $a[j]$ 就是数组的第 $j$ 大元素。可以利用这个特性找出数组的第 $K$ 个元素,这种找第 $K$ 个元素的算法称为快速选择算法。
1 | public int[] getLeastNumbers(int[] arr, int k) { |
1 | /** |
- 时间复杂度:$O(n)$。
- 空间复杂度:$O(1)$,不需要额外空间。
Solution 2 - 堆
应该使用大顶堆来维护最小堆,而不能直接创建一个小顶堆并设置一个大小,企图让小顶堆中的元素都是最小元素。
维护一个大小为 $K$ 的最小堆过程如下:在添加一个元素之后,如果大顶堆的大小大于 $K$,那么需要将大顶堆的堆顶元素去除。
1 | public int[] getLeastNumbers(int[] arr, int k) { |
- 时间复杂度:$O(n\lg k)$。
- 空间复杂度:$O(k)$。
41. 数据流中的中位数
题目描述
求数据流中的中位数。如果从数据流中读出奇数个数值,那么中位数就是所有数值排序之后位于中间的数值。如果从数据流中读出偶数个数值,那么中位数就是所有数值排序之后中间两个数的平均值。
设计一个支持以下两种操作的数据结构:
void addNum(int num):从数据流中添加一个整数到数据结构中。double findMedian():返回目前所有元素的中位数。
1 | Case 1: |
Solution 1 - 快排
题目中已经说了所有数值排序之后…,那排序首先想到什么呢?
1 | // 勉强通过,面试肯定是不行的。 |
- 时间复杂度:$O(n\lg n)$。
- 空间复杂度:
Collections.sort()底层快排 $O(\lg n)$,存储数据 $O(n)$。
Solution 2 - 优先队列/堆
在本问题中,需要将数据流保存在列表中,而且需要保证在添加数据时,列表仍然有序。
在此选择维护两个堆,小顶堆 $A$ 与 大顶堆 $B$,两个堆中各保存列表中一半元素。设元素总数 $N = m + n$,其中 $m$ 与 $n$ 分别为 $A$ 和 $B$ 中的元素个数。
- 小顶堆 $A$ 保存较大的一半元素,长度为 $\frac{N}{2}$ ($N$ 为偶数)或 $\frac{N+1}{2}$($N$ 为奇数)。
- 大顶堆 $B$ 保存较小的一半元素,长度为 $\frac{N}{2}$ ($N$ 为偶数)或 $\frac{N-1}{2}$($N$ 为奇数)。
然后,中位数可以根据 $A, B$ 的堆顶元素计算得到。
算法流程
addNum(num):
- 如果 $m = n$ :需向 $A$ 添加一个元素。实现方法:先将元素 $num$ 插入 $B$ ,然后取出 $B$ 堆顶插入 $A$ ;
- 如果 $m \ne n$ :需向 $B$ 添加一个元素。实现方法:先将元素 $num$ 插入 $A$ ,然后取出 $A$ 堆顶插入 $B$ 。
dindMedian():
- 如果 $m = n$ :$N$ 为偶数,返回
(A.peek() + B.peek()) / 2; - 如果 $m \ne n$ :$N$ 为奇数,返回
A.peek()。
1 | class MedianFinder { |
- 时间复杂度:添加元素 $O(log n)$,获取中位数 $O(1)$。
- 空间复杂度:$O(N)$,存储数据流中的元素。
42. 连续子数组的最大和
输入一个整型数组,数组里有正数也有负数。数组中的一个或连续多个整数组成一个子数组。求所有子数组的和的最大值。
要求时间复杂度为 $O(n)$。
Solution - 动态规划
动态规划解析:
状态定义:设动态规划列表为 $dp$ , $dp[i]$ 代表以元素 $nums[i]$ 为结尾的连续子数组最大和。
转移方程:若 $dp[i-1] \le 0$ ,说明 $dp[i-1]$ 产生负贡献,即 $dp[i-1]+nums[i]$ 还不如 $nums[i]$ 本身大。
$$
dp[i] =
\begin{cases}
dp[i-1]+nums[i] &, dp[i-1]>0 \
nums[i] &, dp[i-1]\le 0
\end{cases}
$$
- 初始状态:$dp[0]=nums[0]$ ,即以 $nums[0]$ 结尾的连续子数组最大和为 $nums[0]$。
- 返回值:$dp$ 中的最大值,即全局最大值。
空间复杂度降低:
- 由于 $dp[i]$ 只与 $dp[i-1]$ 和 $nums[i]$ 有关系,所以可考虑原地修改。
1 | public int maxSubArray(int[] nums) { |
- 时间复杂度:$O(n)$。
- 空间复杂度:$O(1)$。
43. 1~n整数中1出现的次数
题目描述
输入一个整数 $n$ ,求 $1\sim n$ 这 $n$ 个整数的十进制表示中 $1$ 出现的次数。
1 | 输入:n = 12 |
Solution - 递推
将 $1\sim n$ 的个位、十位、百位、…的 $1$ 出现的次数相加,即为 $1$ 出现的总次数。
设数字 $n$ 是 $x$ 位数,记 $n$ 的第 $i$ 位为 $n_i$ ,则可将 $n$ 表示为 $n_xn_{x-1}\cdots n_2n_1$ :
- 称 $n_i$ 为当前位,记为 $cur$ ;
- 将 $n_{i-1}n_{i-2}\cdots n_2n_1$ 称为低位,记为 $low$ ;
- 将 $n_xn_{x-1}\cdots n_{i+1}n_{i+1}$ ,记为 $high$ ;
- 将 $10^i$ 称为位因子,记为 $digit$ 。
某位中 $1$ 出现次数的计算方法:
- 当 $cur=0$ 时,此位 $1$ 的出现次数只由高位 $high$ 决定,表达式为 $high\times digit$。
- 当 $cur=1$ 时,此位 $1$ 的出现次数由高位 $high$ 和低位 $low$ 决定,表达式为 $high \times digit + low + 1$。
- 当 $cur=2,3,4,\cdots,9$ 时,此位 $1$ 出现的次数只由高位 $high$ 决定,表达式为 $(high+1)\times digit$。
1 | public int countDigitOne(int n) { |
- 时间复杂度:$O(\lg n)$,循环内的计算操作使用 $O(1)$,循环次数为 $O(\log_{10} n)$。
- 空间复杂度:$O(1)$,有限的几个变量。
44. 数字序列中某一位的数字
题目描述
数字以 $0123456789101112131415 \dots$ 的格式序列化到一个字符序列中。在这个序列中,第 $5$ 位(从下标 $0$ 开始计数)是 $5$,第 $13$ 位是 $1$,第 $19$ 位是 $4$,等等。
Solution - 迭代
- 将 $101112\dots$ 中的每一位称为数位,记为 $n$ ;
- 将 $10,11,12,\dots$ 称为 数字,记为 $num$ ;
- 数字 $10$ 是一个两位数,称此数字的位数为 $2$ ,记为 $digit$ ;
- 每 $digit$ 位数的起始数字(即: $1,10,100,\dots$ ),记为 $start$。
| 数字范围 | 位数 | 数字数量 | 数位数量 |
|---|---|---|---|
| $1~9$ | $1$ | $9$ | $9$ |
| $10~99$ | $2$ | $90$ | $180$ |
| $100~999$ | $3$ | $900$ | $2700$ |
| $\dots$ | $\dots$ | $\dots$ | $\dots$ |
| $start \sim end$ | $digit$ | $9 \times start$ | $9\times start\times digit$ |
- 位数递推公式:$digit=digit+1$;
- 起始数字递推公式:$start=10\times start$;
- 数位数量计算公式:$count=9\times start \times digit$;
- 可推出各 $digit$ 下的数位数量 $count$ 的计算公式:$count=9\times start \times digit$。
经过以上分析,可将求解分为三步:
- 确定 $n$ 所在数字的位数,记为 $digit$ ;
- 确定 $n$ 所在的数字,记为 $num$ ;
- 确定 $n$ 是 $num$ 中的哪一数位,并返回结果。
1 | public int findNthDigit(int n) { |
- 时间复杂度: $O(\lg n)$ ,所求数位 $n$ 对应数字 $num$ 的位数 $digit$ 最大为 $O(\lg n)$ ;第一步最多循环 $O(\lg n)$ 次;第三步中将 $num$ 转化为字符串使用 $O(\lg n)$ 时间。
- 空间复杂度: $O(\lg n)$ ,将数字 $num$ 转化为字符串 $str$ ,占用 $O(\lg n)$ 的存储空间。
45. 把数组排成最小的数
题目描述
输入一个非负整数数组,把数组里所有数字拼接起来排成一个数,打印能拼接出的所有数字中最小的一个。
Solution - 自定义排序
- 求拼接起来的最小数字,本质上是一个排序问题。
- 判断规则:设 $nums$ 任意两数字的字符串格式 $x$ 和 $y$ ,则
- 若拼接字符串 $x+y>y+x$ ,则 $m>n$ ;
- 反之,若 $x+y<y+x$ ,则 $n<m$ .
- 根据以上规则,套用任何排序方法对 $nums$ 排序即可。
算法流程
- 初始化:字符串列表 $strs$ ,保存各数字的字符串格式;
- 列表排序:应用以上“排序判断规则”,对 $strs$ 执行排序;
- 返回值:拼接 $strs$ 的所有字符串
1 | public String minNumber(int[] nums) { |
- 时间复杂度:$O(N\lg N)$,$N$为最终返回值的字符数量 $strs$ 列表的长度 $\le N$ ;使用快排或内置函数的平均时间复杂度为 $O(N\lg N)$ ,最差为 $O(N^2)$。
- 空间复杂度: $O(N)$ ,字符串列表 $strs$ 占用线性大小的额外空间。
46. 把数字翻译成字符串
题目描述
给定一个数字,我们按照如下规则把它翻译为字符串:$0$ 翻译成 “$a$” ,$1$ 翻译成 “$b$”,$\dots$,$11$ 翻译成 “$l$”,$\dots$,$25$ 翻译成 “$z$”。一个数字可能有多个翻译。请编程实现一个函数,用来计算一个数字有多少种不同的翻译方法。
1 | 输入: 12258 |
动态规划解析
假设数字序列为 $num=x_1x_2\dots x_{i-2}x_{i-1}x_i\dots x_{n-1}{x_n}$ ,例如 $10086=x_1x_2x_3x_4x_5$ 。可以看到的有的数字组合有两种方式,比如 $10086$ 开头的 $1$ 可以单独翻译,但是也可以前两个数字组合 $10$ 一起翻译。
- 假设 $x_1x_2\dots x_{i-2}$ 的翻译方案数量为 $f(i-2)$;
- 假设 $x_1x_2\dots x_{i-2}x_{i-1}$ 的翻译方案数量为 $f(i-1)$。
所以,从末尾来看, $x_{i-2}$ 可以单独翻译,也可以跟 $x_{i-1}$ 一起作为 $x_{i-2}x_{i-1}$ 一起翻译,由排列组合中的“分类相加,分步相乘”可以得到最后结果为两种情况之和,递归关系为:
$$
f(i)=
\begin{cases}
f(i-2)+f(i-1) &, 若\ x_{i-1}x_i \ 可整体翻译 \
f(i-1) &, 若\ x_{i-1}x_i \ 不可整体翻译
\end{cases}
$$
动态规划
- 状态定义:设动态规划列表为 $dp$ , $dp[i]$ 代表以 $x_i$ 为结尾的数字的翻译方案数量。
- 状态转移:
- 若 $x_{i-1}$ 和 $x_i$ 组成的两位数字不可整体翻译,则 $dp[i]=dp[i-1]$;
- 若 $x_{i-1}$ 和 $x_i$ 组成的两位数字可以整体翻译,则 $dp[i]=dp[i-1]+dp[i-2]$ ,当 $x_{i-1}=0$ 时,组成的两位数是无法被翻译的,例如($00,01\dots 09$),因此可翻译的两位数区间为 $[10,25]$。
$$
dp[i]=
\begin{cases}
dp[i-1]+dp[i-2] &, 10x_{i-1}+x_i \in [10,25] \
dp[i-1] &, 10x_{i-1}+x_i \in [0,10) \cup (25,99]
\end{cases}
$$
- 初始值: $dp[0]=dp[1]=1$ ,当 $num$ 第 $1,2$ 位的数字属于 $[10,25)$ 时显然有两种翻译方案,即 $dp[2]=dp[1]+dp[0]=2$ ,而 $dp[1]=1$ ,所以 $dp[0]=1$ 。
- 返回值: $dp[n]$。
Solution 1 -字符串遍历
- 为方便获取数字的各位 $x_i$ ,考虑先将数字 $num$ 转化为字符串 $s$ ,通过遍历 $s$ 实现动态规划。
- 通过字符串切片 $s[i-2:i]$ 获取数字组合 $10x_{i-1}+x_i$ ,通过对比字符串 $ASCII$ 码判断字符串对应的数字区间。
- 空间使用优化:由于 $dp[i]$ 只与 $dp[i-1]$ 有关,因此可使用两个变量 $a,b$ 分别记录 $dp[i],dp[i-1]$ ,两变量交替前进即可。此方法可省去 $dp$ 列表使用的 $O(N)$ 的额外空间。
1 | public int translateNum(int num) { |
- 时间复杂度:$O(n)$,需要遍历一遍字符数组。
- 空间复杂度:$O(n)$。
Solution 2 - 数字求余
上述方法虽然已经节省了 $dp$ 列表的空间占用,但是字符串仍然使用了 $O(N)$ 大小的额外存储空间。
空间复杂度优化
利用求余运算 $num%10$ 和求整运算 $num/10$ ,可获取数字 $num$ 的各位数字(获取顺序为个位、十位、百位…)
因此,可通过 求余 和 求整 运算实现从右向左的遍历计算。
字符串 $s$ 的空间占用也被省去,空间复杂度从 $O(N)$ 降至 $O(1)$ 。
1 | public int translateNum(int num) { |
47. 礼物的最大价值
题目描述
在一个 $m\times n$ 的棋盘的每一格都放有一个礼物,每个礼物都有一定的价值(价值大于 $0$)。你可以从棋盘的左上角开始拿格子里的礼物,并每次向右或者向下移动一格、直到到达棋盘的右下角。给定一个棋盘及其上面的礼物的价值,请计算你最多能拿到多少价值的礼物?
1 | 输入: |
Solution - 动态规划
从题目要求可以发现,某单元格只能从其上方或者左方的单元格到达。设 $f(i,j)$ 为从棋盘左上角走到单元格 $(i,j)$ 的最大累积价值,易得以下地推关系: $f(i,j)$ 等于 $f(i,j-1)$ 和 $f(i-1,j)$ 中的较大值加上当前单元格礼物价值 $grid(i,j)$ .
$$
f(i,j)=max{f(i,j-1), f(i-1,j)}+grid(i,j)
$$
状态定义:设动态规划矩阵 $dp$ , $dp(i,j)$ 代表从棋盘的左上角开始,到达单元格 $(i,j)$ 时能拿到礼物的最大累积价值。
状态转移
- 当 $i=0$ 且 $j=0$ 时,为左上角的起始元素;
- 当 $i=0$ 且 $j \ne 0$ 时,为矩阵第一行元素,每个单元格只可由其左边到达;
- 当 $i\ne 0$ 且 $j=0$ 时,为矩阵第一列元素,每个单元格只可由其上边到达;
- 当 $i \ne 0$ 且 $j\ne 0$ 时,可从左边或者上边到达。
$$
dp(i,j)=
\begin{cases}
grid(i,j) &, i=0,j=0 \
grid(i,j) + dp(i,j-1) &, i=0,j \ne 0 \
grid(i,j) + dp(i-1,j)&, i\ne0,j=0 \
grid(i,j) + dp(i-1,j-1)&, i\ne0,j\ne0
\end{cases}
$$
初始状态: $dp[0][0]=grid[0][0]$ ,即初始价值为左上角的元素。
返回值: $dp[m-1][n-1]$ , $m,n$ 分别为矩阵的行和列,即返回 $dp$ 矩阵右下角的值。
空间复杂度优化:
因为 $dp[i][j]$ 只与 $dp[i-1,j,dp[i][j-1]], grid[i][j]$ 有关系,因此可不用申请 $dp$ 矩阵的空间,直接在原矩阵上原地修改即可,从而将空间复杂度从 $O(MN)$ 降低至 $O(1)$。
1 | public int maxValue(int[][] grid) { |
- 时间复杂度:$O(MN)$。
- 空间复杂度:$O(1)$。
48. 最长不含重复字符的子字符串
题目描述
从字符串中找出一个最长的不包含重复字符的子字符串,计算该最长子字符串的长度。
1 | 输入: "abcabcbb" |
动态规划解析
- 状态定义:设动态规划列表为 $dp$ , $dp[j]$ 代表以字符 $s[j]$ 为结尾的“最长不重复子字符串”的长度。
- 状态转移:固定右边界 $j$ ,设字符 $s[j]$ 左边距离最近的相同字符为 $s[i]$ ,即 $s[i]=s[j]$ 。
- 当 $i <0$ ,即 $s[j]$ 左边无相同字符,则 $dp[j] = dp[j-1]+1$ ;
- 当 $dp[j-1]<j-i$ ,说明 $s[i]$ 在字符串 $dp[j-1]$ 区间之外,则 $dp[j]=dp[j-1]+1$ ;
- 当 $dp[j-1]\ge j-i$ ,说明 $s[i]$ 在子字符串 $dp[j-1]$ 区间之内,则 $dp[j]$ 的左边界由 $s[i]$ 来决定,即 $dp[j]=j-i$ 。
- 当 $i<0$ 时,由于 $dp[j-1]\le j$ 恒成立,因而 $dp[j-1]<j-i$ 恒成立,因此上述三种情况可以合并为:
$$
dp[j] =
\begin{cases}
dp[j-1]+1 &, dp[j-1] < j-i\
j-i &, dp[j-1]\ge j-i
\end{cases}
$$
- 初始状态: $dp[0]=1$ ,即初始不重复子串的长度为 $1$ 。
- 返回值: $max(dp)$ ,即全局的“最长不重复子串”的长度。
观察状态转移方程,可以发现问题转化为:每轮遍历到字符 $s[j]$ 时,如何计算左边界索引 $i$ ?
由于返回值是 $dp$ 中的最大值,因此可借助遍历 $tmp$ 存储 $dp[j]$ ,变量 $res$ 每轮更新最大值即可。
Solution - 1 动态规划
- 哈希表
map:存储字符及其最后一次出现的索引位置。 - 左边界获取方式:遍历到 $s[j]$ 时,通过
map.get(s[j])获取左边界位置。
1 | public int lengthOfLongestSubstring(String s) { |
- 时间复杂度:$O(n)$,需要遍历一遍字符数组。
- 空间复杂度:$O(128)=O(1)$,字符的 $ASCII$ 的范围为 $0 \sim 127$。
Solution - 2 双指针
本质上与方法一类似,不同点在于左边界 $i$ 的定义。
哈希表
map:存储字符及其最后一次出现的索引位置。左指针 $i$ :根据上轮左指针 $i$ 和 $map.get(s[j])$ ,每轮更新左边界,保证 $[i+1, j]$ 内无重复字符且最大。
$$
i= max{ map.get[s[j], i] }
$$更新结果 $res$ :取上轮 $res$ 和本轮双指针区间 $[i+1, j]$ 的宽度(即 $j-i$ )中的最大值
$$
res = max{res, j-i}
$$1
2
3
4
5
6
7
8
9
10
11public int lengthOfLongestSubstring(String s) {
Map<Character, Integer> map = new HashMap<>();
int leftIndex = -1, res = 0;
for (int j = 0; j < s.length(); j++) {
if (map.containsKey(s.charAt(j)))
leftIndex = Math.max(leftIndex, map.get(s.charAt(j))); // 更新左指针 i
map.put(s.charAt(j), j); // 哈希表记录
res = Math.max(res, j - leftIndex);
}
return res;
}时间复杂度:$O(n)$,需要遍历一遍字符数组。
空间复杂度:$O(128)=O(1)$,字符的 $ASCII$ 的范围为 $0 \sim 127$。
49. 丑数
题目描述
我们把只包含质因子 $2、3$ 和 $5$ 的数称作丑数($Ugly\ Number$)。求按从小到大的顺序的第 $n$ 个丑数。
1 | 输入: n = 10 |
Solution - 动态规划
丑数只包含因子 $2,3,5$ ,因此有 丑数 $=$ 某较小丑数 $\times$ 某因子。 有些疑惑 $8$ 为什么也是丑数, $8=2\times4$ ,这可不是只包含因子 $2,3,5$ 。但是同样的 $8=2\times2\times2$ ,此时可以满足因子只包含 $2$ 。(强行解释,所以丑数也许还可以理解为 若干个 $2$ 乘以若干个 $3$ 乘以若干个 $5$,即 $ugly = 2^x \times 3^y \times 5^z$)。
设已知长度为 $n$ 的丑数序列 $x_1,x_2,\dots,x_n$ ,求第 $n+1$ 个丑数 $x_{n+1}$ 。根据递推性质,丑数 $x_{n+1}$ 只可能是以下三种情况之一(索引 $a,b,c$ 为未知数):
$$
x_{n+1} =
\begin{cases}
x_a \times 2, & a \in [1,n] \
x_b \times 3, & b \in [1,n] \
x_c \times 5, & c \in [1,n]
\end{cases}
$$
由于 $x_{n+1}$ 是最接近 $x_n$ 的丑数,因此索引 $a,b,c$ 需满足以下条件:
$$
\begin{cases}
x_a \times 2 > x_n \ge x_{a-1} \times 2, & 即\ x_a\ 为首个乘以\ 2\ 后大于\ x_n\ 的丑数 \
x_b \times 3 > x_n \ge x_{c-1} \times 3, & 即\ x_b\ 为首个乘以\ 3\ 后大于\ x_n\ 的丑数 \
x_c \times 5 > x_n \ge x_{c-1} \times 5, & 即\ x_c\ 为首个乘以\ 5\ 后大于\ x_n\ 的丑数
\end{cases}
$$
若索引 $a,b,c$ 满足以上条件,则可使用递推公式计算下个丑数 $x_{n+1}$ ,其为三种情况中的最小值,即:
$$
x_{n+1} = min{x_a\times2,x_b\times3,x_c\times5}
$$
因此,可设置指针 $a,b,c$ 指向首个丑数(即 $1$ ),循环根据递推公式得到下个丑数,并每轮将对应指针执行 $+1$ 操作。
动态规划解析
- 状态定义:设动态规划列表为 $dp$ , $dp[i]$ 代表第 $i+1$ 个丑数。
- 状态转移:
- 当索引 $a,b,c$ 满足以下条件时, $dp[i]$ 为三种情况的最小值;
- 每轮计算 $dp[i]$ 后,需要更新索引 $a,b,c$ 的值,使其始终满足方程条件。实现方法:分别独立判断 $dp[i]$ 和 $dp[a]\times2,dp[b]\times3,dp[c]\times5$ 的大小关系,若相等则将对应索引 $a,b,c$ 加 $1$ 。
$$
\begin{cases}
dp[a] \times 2 > dp[i-1] \ge dp[a-1] \times 2 \
dp[b] \times 3 > dp[i-1] \ge dp[b-1] \times 3 \
dp[c] \times 5 > dp[i-1] \ge dp[c-1] \times 5
\end{cases} \
dp[i] = min{dp[a]\times2, dp[b]\times3,dp[c]\times5 }
$$
- 初始状态: $dp[0] = 1$ ,即第一个丑数为 $1$ 。
- 返回值: $dp[n-1]$ , 即返回第 $n$ 个丑数。
1 | public int nthUglyNumber(int n) { |
- 时间复杂度:$O(N)$,其中 $N = n$ ,动态规划需要遍历计算 $dp$ 列表。
- 空间复杂度: $O(N)$ ,长度为 $N$ 的 $dp$ 列表使用 $O(N)$ 的辅助空间。
50. 第一个只出现一次的字符
题目描述
在字符串 s 中找出第一个只出现一次的字符。如果没有,返回一个单空格。 $s$ 只包含小写字母。
1 | s = "abaccdeff" |
Solution - 计数
吐槽一句,当时面试映客直播时[电话面],第一次在面试中问算法,第一道题 $LRU$ 算法,第二道就是这题,然后我几乎不假思索地就说出了这个方法:
- 先申请一个 $256$ 长度的辅助数组($256$ 是扩展的 $ASCII$ 码数量)。
- 扫描字符串,以字符串中的字符的 $ASCII$ 码为下标,每出现一次将下标上的值加 $1$。
- 再扫描一遍字符数组,仍然用字符 $ASCII$ 码做下标去检查是否为 $1$,是的话则直接返回。扫描结束后无结果则返回空字符串。
如果手写代码的话应该是没问题的,但是当时被面试官一直追着问,没给仔细思考的时间,没有手写代码,然后她给我大概举了个 "cbbadfdf" 的例子。
我本意是按字符的 $ASCII$ 码作为下标去辅助数组中查找的,结果被带的脑子有点乱,在临时讲思路的时候说成了从头到尾扫描,因为"c、a"都出现了一次,"a"的 $ASCII$ 为 $97$ 在 "c" 的 $ASCII$ 码 $99$ 前面,把自己绕进去了。
$NOTE$ : 在面试中问到算法不要急,如果面试官给时间的话最好把代码手写出来,或者写出大概步骤,如果一直追着问不给时间的话多半是已经凉了。
1 | public char firstUniqChar(String s) { |
- 时间复杂度:$O(n)$,遍历了一遍字符串。
- 空间复杂度:将字符串转化成字符数组占用 $O(n)$,辅助数组 $count$ 占用 $O(1)$,总体 $O(n)$。其实也可以不使用 $chars$ 这个辅助数组。
Solution 2 - 无序哈希
算法流程
- 初始化 $HashMap$,记为 $dic$;
- 遍历字符串
- 如果字符 $key$ 已在 $dic$ 存在,将其对应的 $value$ 置为 $false$,代表出现了不止一次;
- 如果字符 $key$ 未在 $dic$ 存在,将其对应的 $value$ 置为 $true$,代表至今只出现了一次。
- 再次遍历字符串,以字符作为 $key$ 查找 $value$ 是否为 $true$。
- 为 $true$,代表只出现了一次,返回结果。
- 为 $false$,代表出现了不止一次;若全为 $false$,则返回
" "。
1 | public char firstUniqChar(String s) { |
- 时间复杂度:$O(n)$。
- 空间复杂度:$O(n)$。
Solution 3 - 有序哈希
思路与无序哈希相同,时空复杂度也相同,只是用 $LinkedHashMap$ 减少了再次遍历的次数,即时间复杂度的常数项。
1 | public char firstUniqChar(String s) { |
- 时间复杂度:$O(n)$。
- 空间复杂度:$O(n)$。
51. 数组中的逆序对
题目描述
在数组中的两个数字,如果前面一个数字大于后面的数字,则这两个数字组成一个逆序对。输入一个数组,求出这个数组中的逆序对的总数。
1 | 输入: [7,5,6,4] |
Solution 1 - 归并排序
使用暴力搜索思想的代码很容易写出来,但是看数组规模最大为 $50000$,因为 $O(n^2)$ 的代码不可取。
归并排序
「归并排序」是分治思想的典型应用,它包含三个步骤:
- 分解:待排序的区间为 $[l,\ r]$,令 $m=\lfloor \frac{l+r}{2} \rfloor$,将区间分为 $[l, m]$ 与 $[m + 1, r]$;
- 解决:使用归并排序递归地排序两个子序列;
- 合并:把两个已经排序好的子序列 $[l, m]$ 和 $[m + 1, r]$ 进行合并。
在待排序序列长度为 $1$ 时,递归开始回退。
具体思路
将「归并排序」与「求逆序对」相关联的关键就在于「归并」中「并」的过程。通过如下实例来理解。
假设有两个已排序的序列等待合并,这两个序列分别是 $L={8,12,16,22,100 }$ 和 $R={ 9,26,55,64,91 }$。使用 lPtr 与 rPtr 分别指向 $L、R$ 首部第一个元素。记已经合并好的部分为 $M$。
1 | L = [8, 12, 16, 22, 100] R = [9, 26, 55, 64, 91] M = [] |
可以发现 $L[lPtr]=8 < R[rPtr]=9$,于是将 $lPtr$ 指向的元素加入 $M$。
1 | L = [8, 12, 16, 22, 100] R = [9, 26, 55, 64, 91] M = [8] |
把 $8$ 加入 $M$ 之后发现 $R$ 中没有数字比 $8$ 小,所以 $8$ 对于统计数组中「逆序对数量」的贡献为 $0$ 。继续下一次迭代,将 $9$ 加入 $M$ ,此时 $L[lPtr]=12 < R[rPtr]=26$ 。于是将 $12$ 加入 $M$ ,它对「逆序对数量」的贡献为:lPtr 相对于 $R$ 中首位置偏移量,即 $lPtr$ 自身。(此时 $R$ 中位于 rPtr 左边的数字均比 $12$ 小,即构成「逆序对」,而此时只有 $9$ 。)
1 | L = [8, 12, 16, 22, 100] R = [9, 26, 55, 64, 91] M = [8, 9] |
「贡献度」 的计算方式
当前 lPtr 指向的数字比 rPtr 小,但是比 $R$ 中 [0 ... (rPtr - 1)] 的其他数字大,[0 ... (rPtr - 1)] 的其他数字本应当排在 lPtr 对应数字的左边,但是它排在了右边,所以这里就贡献了 rPtr 个逆序对。
1 | public int reversePairs(int[] nums) { |
- 时间复杂度: $O(n\lg n)$ ,利用到归并排序。
- 空间复杂度: $O(n)$ ,除去递归栈之外,还用到了临时数组 $tmp$ 。
Solution 2 - 离散化树状数组
点击链接自行查看
52. 两个链表的第一个公共节点
题目描述
输入两个链表,找出它们的第一个公共节点。如下面的两个链表在 $c1$ 相交。

Solution - 双指针
看到这段代码就想起一段话:
“听闻远方有你,动身跋涉千里。我吹过你吹过的风,这算不算相拥?我走过你走过的路,这算不算相逢?”
1 | /** |
- 时间复杂度:$O(L_1+L_2+C)$,解释在注释里。
- 空间复杂度:$O(1)$。
53 - I. 在排序数组中查找数字 I
题目描述
统计一个数字在排序数组中出现的次数。
1 | 输入: nums = [5,7,7,8,8,10], target = 8 |
Solution - 二分搜索
继续说,看到一次说一次:看见有序数组,首先想到二分搜索。
对于二分搜索,首先想到如下几个思路:
- 直接二分搜索,找到 $target$ 的话,记录下索引,然后从索引开始往前搜一搜,再往后搜一搜;
- 窗口:二分找到比 $target$ 大一点的右边界 $right$,比 $target$ 小一点的左边界 $left$,然后计算窗口的大小。
在此选择第二种思路。因为 $LeetCode$ 的方法名中的参数均为 $int$,所以比 $target$ 大一点与小一点的可以选择小数,作为插入位置,当然,这不是真的要插入,而是要限定区间。
1 | public int search(int[] nums, int target) { |
- 时间复杂度:$O(\log_2 n)$。
- 空间复杂度:$O(1)$。
53 - II. 0~n-1 中缺失的数字
题目描述
一个长度为 $n-1$ 的递增排序数组中的所有数字都是唯一的,并且每个数字都在范围 $0 \sim n-1$ 之内。在范围 $0 \sim n-1$ 内的 $n$ 个数字中有且只有一个数字不在该数组中,请找出这个数字。
1 | 输入: [0,1,3] |
Solution 1 - 暴力搜索
题目中已经说了是递增排序数组,并且唯一,而数组的下标本身就是从 $0 \sim n-1$ 递增的。从题目中可以读到数组中的 $index-value$ 应该是相等的,如果某个索引 $index$ 处的 $value$ 不相等的话,则是缺失的数字。
1 | public int missingNumber(int[] nums) { |
- 时间复杂度:$O(n)$,遍历一遍数组。
- 空间复杂度:$O(1)$。
Solution 2 - 二分搜索
继续说,看到一次说一次:看见有序数组,首先想到二分搜索。
根据题意,可以将该有序数组划分为有序数组与无序数组两部分:
- 左子数组: 即 $nums[i] = i$;
- 右子数组: 即 $nums[i] \ne i$。
寻找缺失的数字等价于右子数组的首位元素。
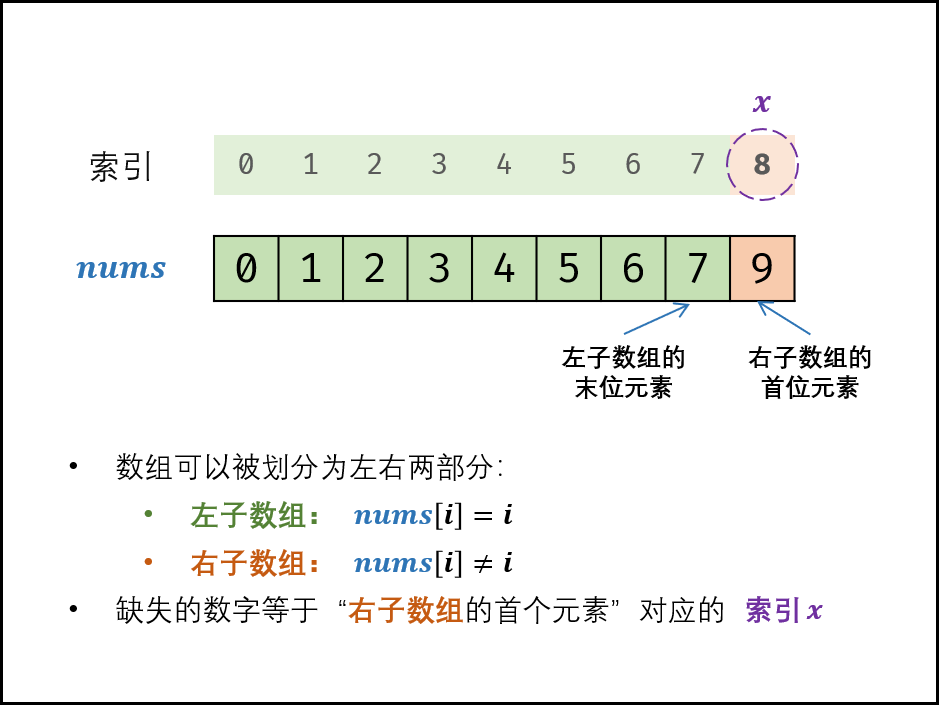
1 | public int missingNumber(int[] nums) { |
- 时间复杂度:$O(n)$,遍历一遍数组。
- 空间复杂度:$O(1)$。
54(🌲). 二叉搜索树的第 k 大节点
题目描述
给定一棵二叉搜索树,请找出其中第 $k$ 大的节点。
1 | 输入: root = [3,1,4,null,2], k = 1 |
Solution 1 - 中序遍历
$NOTE$: 二叉搜索树的中序遍历结果为递增序列。
既然中序遍历的结果是递增序列,那么遍历一遍返回倒数第 $k$ 个就 $Ok$ 了。
1 | public class Solution { |
- 时间复杂度:$O(n)$,需要访问每个节点一次。
- 空间复杂度:$O(n)$,当搜索树退化为链表时,$list$ 存储节点值需要 $O(n)$,递归深度达到 $O(n)$。
Solution 2 - 中序遍历倒序
大佬又有一种提前返回剪枝的做法。
提到中序遍历,可能会有不少人只会想到 左、根、右 这种顺序,但是其实 右、根、左 也是中序遍历。
既然二叉搜索树的中序遍历结果为递增序列,那么二叉搜索树的中序遍历结果的逆序为递减序列。
1 | // 打印中序遍历 |
接下来需要做的就是递减 $k$ 值,每访问一个节点就进行 k-- 操作,等到 $k=0$ 时,自然就是第 $k$ 大的节点了。
1 | public class Solution { |
- 时间复杂度:$O(n)$,当搜索树退化为链表时,无论 $k$ 值几何,递归深度均为 $n$。
- 空间复杂度:$O(n)$,当搜索树退化为链表时,$list$ 存储节点值需要 $O(n)$,递归深度达到 $O(n)$。
55(🌲) - I. 二叉树的深度
输入一棵二叉树的根节点,求该树的深度。从根节点到叶节点依次经过的节点(含根、叶节点)形成树的一条路径,最长路径的长度为树的深度。
给定二叉树 [3,9,20,null,null,15,7]
1 | 3 |
Solution 1 - DFS
树的深度 $=$ 左右子树深度的最大值$ + 1$。
1 | public int maxDepth(TreeNode root) { |
- 时间复杂度:$O(n)$,每个节点访问一次。
- 空间复杂度:$O(n)$,当树退化为链表时,递归深度达到 $n$。
Solution 2 - BFS
其实就是利用树的层次遍历,同时设置一个层高 $level$,每向下一层,$level+1$。
1 | public int maxDepth(TreeNode root) { |
- 时间复杂度:$O(n)$,每个节点访问一次。
- 空间复杂度:$O(n)$,当树为满二叉树时,最底层节点数达到 $n/2$。
55(🌲) - II. 平衡二叉树
题目描述
输入一棵二叉树的根节点,判断该树是不是平衡二叉树。如果某二叉树中任意节点的左右子树的深度相差不超过 $1$,那么它就是一棵平衡二叉树。
给定二叉树 [3,9,20,null,null,15,7]
1 | 3 |
Solution 1 - DFS
这题其实是上一题的扩展,上一题可以用于求子树的深度,而这一题要做的是判断两棵子树的树高之差,即是否满足:
$$
|maxDepth(root.left)-maxDepth(root.right)|\le 1
$$
1 | public boolean isBalanced(TreeNode root) { |
- 时间复杂度:$O(n\lg n)$。
- 空间复杂度:$O(n)$。
Solution 2 - 后序遍历+剪枝
此方法为本题的最优解法,但剪枝的方法不易第一时间想到。
思路是对二叉树做后序遍历,从底至顶返回子树深度,若判定某子树不是平衡树则 “剪枝” ,直接向上返回。
算法流程
recur(root)
- 返回值:
- 当节点 $root$ 左 / 右子树的深度差 $\leq 1$ :则返回当前子树的深度,即节点 $root$ 的左 / 右子树的深度最大值 $+1$;
- 当节点 $root$ 左 / 右子树的深度差 $>2$ :则返回 $-1$ ,代表此子树不是平衡树 。
- 终止条件:
- 当 $root$ 为空:说明越过叶节点,因此返回高度 $0$ ;
- 当左(右)子树深度为 $-1$ :代表此树的 左(右)子树 不是平衡树,因此剪枝,直接返回 $-1$ 。
isBalanced(root)
- 若
recur(root) != -1,则说明此树平衡,返回 $true$; 否则返回 $false$。
1 | public boolean isBalanced(TreeNode root) { |
时间复杂度:$O(n)$, $n$ 为树的节点数;最差情况下,需要递归遍历树的所有节点。
空间复杂度:$O(n)$,最差情况下(树退化为链表时),系统递归需要使用 $O(n)$ 的栈空间。
56 - I. 数组中数字出现的次数
题目描述
一个整型数组 $nums$ 里除两个数字之外,其他数字都出现了两次。请写程序找出这两个只出现一次的数字。要求时间复杂度是 $O(n)$,空间复杂度是 $O(1)$。
1 | 输入:nums = [4,1,4,6] |
Solution - 分组异或
- 题目要求:时间复杂度 $O(n)$, 空间复杂度 $O(1)$,因此不能用 $Map$ 以及双重循环。
- 选择分组异或操作,而在异或操作中有以下几条运算规则:
- A $\oplus$ A = $0$
- A $\oplus$ B $\oplus$ C = A $\oplus$ (B $\oplus$ C)
- 由于数组中存在两个不一样的且只出现一次的数字,其他的数字都是两两出现,而成对的数字异或结果为 $0$ ,所以全体数字异或的结果等于两个只出现一次的数字的异或结果。
1 | 4 ^ 1 ^ 4 ^ 6 = 1 ^ 6 |
1 | public int[] singleNumbers(int[] nums) { |
- 时间复杂度:$O(n)$,扫描了两遍数组。
- 空间复杂度:$O(1)$,只用到了有限个变量。
56 - II. 数组中数字出现的次数 II
题目描述
在一个数组 $nums$ 中除一个数字只出现一次之外,其他数字都出现了三次。请找出那个只出现一次的数字。
1 | 输入:nums = [3,4,3,3] |
Solution 1 - 位运算
解题思路
如果一个数字出现了 $3$ 次,那么这个数字的二进制表示的每一位 $0\ or\ 1$ 也出现三次。如果把所有出现三次的数字的二进制表示的每一数位上的数字相加(和要么为 $0$ 要么为 $3$ 的倍数),那么每一位的和都能被 $3$ 整除。
- 如果某一数位上的数字和能被 $3$ 整除,那么那个只出现 $1$ 次的数字的二进制表示中的当前位为 $0$。因为不是 $0$ 的话,那只能是 $1$ 。而在前面已经提到过,所有出现三次的数字的二进制表示的每一数位上的数字和要么为 $0$ 要么为 $3$ 的倍数,而
+1后则不能被 $3$ 整除。 - 否则为 $1$ 。
算法流程
- 使用与运算,可获取二进制数字 $num$ 的最右位 $n_1$,即
n_1 = num & 1;; - 结合无符号右移,可获取 $num$ 所有位的值,即 $n_1 \sim n_{32}$ ,即
num = num >>> 1; - 建立长度为 $32$ 的数组 $counts$ ,用于统计所有数字的二进制位中 $1$ 出现次数。
- 将 $counts$ 中的各元素对 $3$ 求余,则结果为”只出现 $1$ 次的数字的各二进制位。“
- 利用 $左移操作$ 与 $或运算$ ,将 $counts$ 中的 $0\ or \ 1$ 恢复成结果。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19public int singleNumber(int[] nums) {
if (nums == null || nums.length == 0)
throw new IllegalArgumentException("数组不合法.");
int[] counts = new int[32];
for (int num : nums) {
for (int j = 0; j < 32; j++) {
counts[j] += num & 1;
num >>>= 1;
}
}
// PS: 在这里使用 mod = 3,只需要修改 mod 的值,就成为解决
// "除了一个数字以外,其余数字都出现 m 次" 的通用方法。
int res = 0, mod = 3;
for (int i = 0; i < 32; i++) {
res <<= 1;
res |= counts[31 - i] % mod;
}
return res;
} - 时间复杂度: $O(n)$ ,其中 $n = len(nums)$ 。遍历数组一遍,每个数字需要进行常数个位运算,每个操作消耗 $O(1)$ 。
- 空间复杂度: $O(1)$ ,数组 $counts$ 长度为 $32$ ,常数级别。
Solution 2 - 有限状态自动机
点击链接自行查看
57 - I. 和为 s 的两个数字
题目描述
输入一个递增排序的数组和一个数字 $s$,在数组中查找两个数,使得它们的和正好是 $s$。如果有多对数字的和等于 $s$,则输出任意一对即可。
1 | 输入:nums = [2,7,11,15], target = 9 |
Solution - 对撞指针
之前常说,看到排序数组首先想到二分法,但是这里选择另一种思路,双指针中的对撞指针。
本题当然也可以使用 $LeetCode$ 第一题的方法求解,但是空间复杂度为 $O(n)$。
算法流程
- 初始化:左指针 $left=0$ ,右指针 $right=nums.length-1$ ;
- 相向而行:判断 $target$ 与 $nums[left] + nums[right]$ 的关系
- 若 $target = nums[left]+nums[right]$ ,则返回数组 $[nums[left],nums[right]]$ ;
- 若 $target > nums[left]+nums[right]$ ,和偏小,则左指针向右移动;
- 若 $target < nums[left]+nums[right]$ ,和偏大,则右指针向左移动。
- 返回值:如果上一步中没有进行 $return$ 操作的话,说明没有找到符合条件的值,返回空数组。
1 | public int[] twoSum(int[] nums, int target) { |
- 时间复杂度:$O(n)$,扫描一遍数组。
- 空间复杂度:$O(1)$,只用到了两个变量。
57 - II. 和为 s 的连续正数序列
题目描述
输入一个正整数 $target$ ,输出所有和为 $target$ 的连续正整数序列(至少含有两个数)。
序列内的数字由小到大排列,不同序列按照首个数字从小到大排列。
1 | 输入:target = 9 |
Solution - 滑动窗口
想必读者能够从头看到这里的话,已经不需要再介绍滑动窗口的概念了。本题所利用到的滑动窗口有以下几点需要关注,假设窗口内的所有数字之和为 $sum$ :
- 当 $sum < target$时:需要扩大窗口,窗口的右边界需要向右移动。
- 当 $sum > target$时:需要缩小窗口,窗口的左边界需要向右移动。
- 当 $sum = target$时:记录此时窗口中的所有元素。
经过上面三步之后可能有人要问:扩大窗口时左边界向左移动不行吗?缩小窗口时右边界向左移动不行吗?
这样的话当然是可以的,但是最好不要回溯,这样的话很难保证滑动窗口 $O(n)$ 的复杂度。
1 | public int[][] findContinuousSequence(int target) { |
- 时间复杂度:$O(n)$。
- 时间复杂度:$O(1)$。
58 - I. 翻转单词顺序
题目描述
输入一个英文句子,翻转句子中单词的顺序,但单词内字符的顺序不变。为简单起见,标点符号和普通字母一样处理。例如输入字符串 “I am a student.“,则输出”student. a am I“。
1 | 输入: " hello world! " |
Solution - 双指针
「逆序」相关的题目可以使用「栈」来实现,但是这往往需要再去操作「栈」,引入额外的时间开销。这里选择双指针倒序遍历,在一次遍历中完成题目要求。
算法流程
- 前置工作:去除字符串首尾多余空格;
- 初始化:建立两个指针 $i = j = s.length - 1$ ,指向字符串尾部,用来指示每个单词的左右边界,结果集 $res$。
- 倒序遍历:指针 $i$ 作为较靠左的指针,向左搜索 空格,在搜索到空格后,
- 将 $i, j$ 之间的单词加入结果中;
- 让 $j$ 移动到 $i$ 所在的位置。
- 返回值:返回结果集 $res$。
1 | public String reverseWords(String s) { |
- 时间复杂度: $O(n)$ ,其中 $n=s.length()$。
- 空间复杂度: $O(n)$ , $StringBuilder$ 并不作为最后结果直接返回,而是中间数据结构。
58 - II. 左旋转字符串
题目描述
字符串的左旋转操作是把字符串前面的若干个字符转移到字符串的尾部。请定义一个函数实现字符串左旋转操作的功能。比如,输入字符串 “$abcdefg$” 和数字 $2$,该函数将返回左旋转两位得到的结果 “$cdefgab$”。
1 | 输入: s = "abcdefg", k = 2 |
Solution 1 - API
1 | public String reverseLeftWords(String s, int n) { |
- 时间复杂度:$O(N)$,其中 $N = s.length()$ 。
- 空间复杂度:$O(N)$,其中 $N = s.length()$ 。
Solution 2 - 反转
首先需要一个交换字符首尾字符的方法 reverse(char[] chars, int i, int j),它的作用是交换字符数组首尾的字符,并且 $i, j$ 向终点收缩。
这种思想是基于这样一个事实,仍然拿 s = "abcdefg", n = 2 为例。
1 | 第一次交换:ab cdefg 交换前 2 个字符 => ba cdefg |
所以接下来需要做的就是
1 | class Solution { |
- 时间复杂度:$O(N)$,其中 $N = s.length()$ 。需要遍历两遍数组。
- 空间复杂度:$O(N)$,其中 $N = s.length()$ 。因为
Java中的String不可以直接修改,所以用chars辅助存储。
59 - I. 滑动窗口的最大值
题目描述
给定一个数组 $nums$ 和滑动窗口的大小 $k$,请找出所有滑动窗口里的最大值。
1 | 输入: nums = [1,3,-1,-3,5,3,6,7], 和 k = 3 |
Solution 1 - 暴力解法
设窗口为 $[i, j]$,最大值为 $x_j$ 。当窗口向右移动一格后变为 $[i+1, j+ 1]$ ,即窗口内新增了 $nums[j+1]$ ,消失了 $nums[i]$ 。
若仅向窗口内添加了 $nums[j]$ ,则新窗口最大值仅需比较一次即可确定。即:
$$
x_{j+1} = max(x_j, nums[j+1])
$$
但是消失的 $nums[i]$ 可能刚好就是最大值 $x_j$ ,因此需要通过遍历的方式再次寻找窗口中的最大值。
1 | public int[] maxSlidingWindow(int[] nums, int k) { |
- 时间复杂度:$O(nk)$。$k$ 为滑动窗口大小。
- 空间复杂度:$O(1)$,
res作为最后返回结果,不算入空间复杂度。而每次的窗口仍是在原数组上操作。
Solution 2 - 单调队列
不难发现暴力解法中搜索窗口最大值的时间复杂度为 $O(k)$ ,遍历数组又必不可少,所以如果想要继续降低复杂度,突破口就在于降低寻找窗口最大值的复杂度。理想情况是从 $O(k)$ 降低到 $O(1)$ 。
在「30. 包含 min 函数的栈」实现了 $O(1)$ 获取最小值,同理,也可以以 $O(1)$ 方式获得窗口中的最大值。
窗口对应的数据结构式双端队列,在此使用单调队列。在遍历数组的过程中,每轮保证单调队列 $deque$ :
- $deque$ 仅包含窗口内出现过的元素。每当窗口移动,滑过 $nums[i-1]$ 时,将 $deque$ 内 $nums[i]$ 对应的元素一起删除(如果存在的话)。
- $deque$ 内的元素非严格递减。每当窗口移动,新增 $nums[j+1]$ 时,需要将 $deque$ 内所有小于 $nums[j+1]$ 的元素删除。
算法流程
- 初始化:双端队列 $deque$ ,结果集 $res$ ;
- 滑动窗口:左边界范围 $i \in [1 - k, n + 1 - k]$,右边界范围 $j \in [0, n - 1]$
- 若 $i > 0$ 且队首元素 $deque[0] = $ 被删除的元素 $nums[i - 1]$ ,将队首元素出队;
- 删除 $deque$ 内所有小于 $nums[j]$ 的元素,保持 $deque$ 的单调性;
- 将 $nums[j]$ 添加至 $deque$ 尾部;
- 若已形成窗口( $i \ge 0$ ),将窗口最大值( $deque[0]$ )添加至结果集 $res$ 。
- 返回值:返回结果集 $res$ 。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15public int[] maxSlidingWindow(int[] nums, int k) {
if (nums == null || nums.length == 0 || k <= 0)
return new int[0];
Deque<Integer> deque = new LinkedList<>();
int[] res = new int[nums.length + 1 - k];
for (int j = 0, i = 1 - k; j < nums.length; i++, j++) {
if (i > 0 && deque.peekFirst() == nums[i] - 1)
deque.removeFirst();
while (!deque.isEmpty() && deque.peekLast() < nums[j])
deque.removeLast(); // 保持单调性
if (i >= 0)
res[i] = deque.peekFirst(); // 记录窗口的最大值
}
return res;
}
- 时间复杂度: $O(n)$ ,其中 $n=len(nums,)$。遍历 $nums$ 需要 $O(n)$ ,每个元素仅入队出队一次,因此单调队列 $deque$ 占用 $O(2n)$ 。
- 空间复杂度: $O(k)$ ,双端队列最多同时存储 $k$ 个元素。(滑动窗口的大小)
59 - II. 队列的最大值
题目描述
请定义一个队列并实现函数 max_value 得到队列里的最大值,要求函数 max_value、push_back 和 pop_front 的均摊时间复杂度都是 $O(1)$。
若队列为空,pop_front 和 max_value 需要返回 $-1$。
1 | 输入: |
Solution - 辅助队列
- 基础的的
push_back与pop_front方法可以用队列queue自带的offer()与poll()以 $O(1)$ 实现 - 维护一个单调双向队列
deque,保证max_value()操作在 $O(1)$ 的时间内完成,此时需要保证:- 在向
queue添加元素时,维护deque的单调性,假设offer()的元素为 $x$,那么需要移除deque中所有小于x的元素。 - 在
queue出队时,如果出队的元素与deque的首元素相同,则移除deque中队首元素。
- 在向
1 | class MaxQueue { |
- 时间复杂度:$O(1)$。
- 空间复杂度:$O(1)$。
60. n 个骰子的点数
题目描述
把 $n$ 个骰子扔在地上,所有骰子朝上一面的点数之和为 $s$。输入 $n$,打印出 $s$ 的所有可能的值出现的概率。
用一个浮点数数组返回答案,其中第 $i$ 个元素代表这 $n$ 个骰子所能掷出的点数集合中第 $i$ 小的那个的概率。
1 | 输入: 1 |
Solution - 动态规划
先假设投掷两枚骰子,假设 $f(n,k)$ 表示投掷 $n$ 枚骰子 🎲 时,点数和 $k$ 出现的次数,如果只有 $1$ 枚骰子的话,出现 $1-6$ 的概率均为 $1/6$, 这里先来模拟 $n=2$ 来计算 $k=4$ 和 $k=5$ 的情况,那么有:
$$
\begin{cases}
f(2,4)&=f(1,1)+f(1,2)+f(1,3) \
f(2,5)&=f(1,1)+f(1,2)+f(1,3)+f(1,4)
\end{cases}
$$
可以看到其中出现了大量的重复计算与子结构,所以考虑使用动态规划的方法来解决。
动态规划解析
- 状态定义:设 $f(n,k)$ 表示投掷 $n$ 枚骰子时,点数和 $k$ 出现的次数;
- 状态转移:上面选择了 $f(n,k)$ 作为状态,当投掷 $n$ 枚骰子时需要依靠 $n-1$ 枚骰子时的状态,同时第 $n$ 枚骰子有 $1、2、3、4、5、6$ 六种取值,所以状态转移可以表示为:
$$
f(n,k)=f(n-1,s-1)+f(n-1,s-2)+f(n-1,s-3)+f(n-1,s-4)+f(n-1,s-5)+f(n-1,s-6)
$$
- 初始状态:$f(1,k)=1$,其中 $k=1、2、3、4、5、6$。
- 概率:$p(n,k)=\frac{f(n,k)}{6^n}$。
1 | public double[] twoSum(int n) { |
- 时间复杂度:$O(n^2)$。
- 空间复杂度:$O(n^2)$。
61. 扑克牌中的顺子
题目描述
从扑克牌中随机抽 $5$ 张牌,判断是不是一个顺子,即这 $5$ 张牌是不是连续的。$2\sim 10$为数字本身,$A$ 为 $1$,$J$ 为 $11$,$Q$ 为 $12$,$K$ 为 $13$,而大、小王为 $0$ ,可以看成任意数字。$A$ 不能视为 $14$。
1 | 输入: [1,2,3,4,5] |
解题思路
根据题意,此 $5$ 张牌是顺子的 充分条件 如下:
- 除大小王外,所有牌无重复;
- 设此 $5$ 张牌中最大的牌为 $max$ ,最小的为 $min$ (大小王除外),则需满足:
$$
max-min<5
$$
因此,可将原问题转化为:此 $5$ 张牌是否满足以上两个条件?
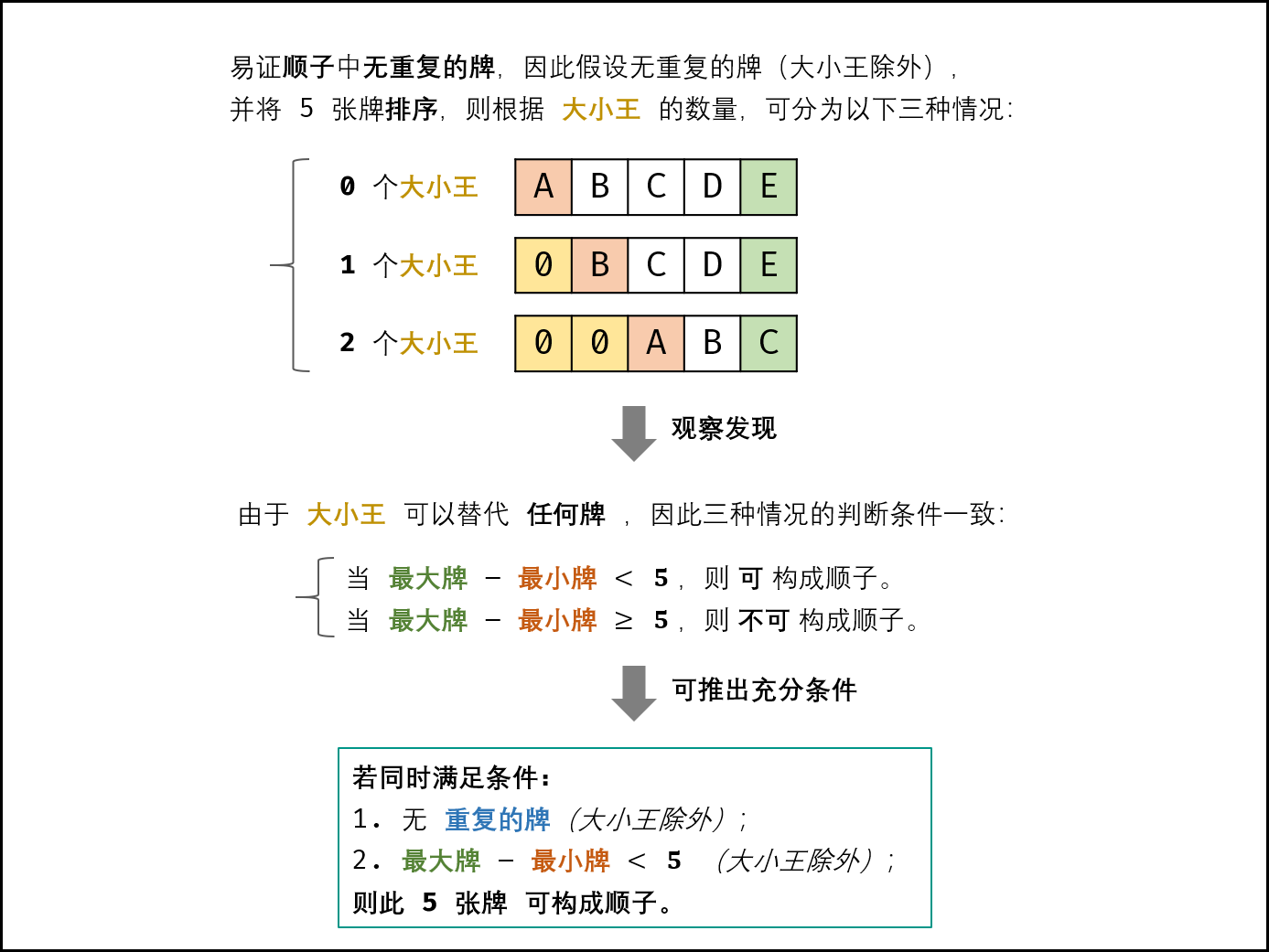
Solution - 集合 Set + 遍历
算法流程
- 遍历五张牌,遇到大小王直接跳过;
- 判别重复:利用 $Set$ 判重;
- 获取最大与最小值:借助辅助变量 $max,min$ ,遍历五张牌即可。
1 | public boolean isStraight(int[] nums) { |
- 时间复杂度: $O(n=5)=O(1)$ 。
- 空间复杂度: $O(n=5)=O(1)$ 。
62. 圆圈中最后剩下的数字
题目描述
$0,1,\dots,n-1$ 这 $n$ 个数字排成一个圆圈,从数字 $0$ 开始,每次从这个圆圈里删除第 $m$ 个数字。求出这个圆圈里剩下的最后一个数字。
例如,$0、1、2、3、4$ 这 $5$ 个数字组成一个圆圈,从数字 $0$ 开始每次删除第 $3$ 个数字,则删除的前 $4$ 个数字依次是 $2、0、4、1$,因此最后剩下的数字是 $3$。
1 | 输入: n = 5, m = 3 |
限制条件:$1 \le n \le 10^5, 1 \le m \le 10^6$。
Solution 1 - 模拟
这个问题是以弗拉维奥·约瑟夫命名的,他是 $1$ 世纪的一名犹太历史学家。他在自己的日记中写道,他和他的40个战友被罗马军队包围在洞中。他们讨论是自杀还是被俘,最终决定自杀,并以抽签的方式决定谁杀掉谁。约瑟夫斯和另外一个人是最后两个留下的人。约瑟夫斯说服了那个人,他们将向罗马军队投降,不再自杀。约瑟夫斯把他的存活归因于运气或天意,他不知道是哪一个。- 约瑟夫环 - Wikipedia
其实 Wikipedia 已经给出了这道题的两种解决方案,一是链表模拟,二是数学反演。
假设当前删除的索引是 $idx$ ,下一个待删除的数字索引是 $idx+m$ ,由于删除了当前位置的数字 $x$ , $x$ 之后的数字将会向前移动一位,所以下一个待删除的数字索引其实是 $idx+m-1$ 。因为到达末尾后会从再次从头开始数,有 环 存在,所以需要对环的周长取模,即 $(idx+m-1)\ mod\ n$ 。
算法流程
- 初始化:初始化约瑟夫环;
- 循环模拟:在这个过程中
- 找到下一个待删除的索引 $(idx + m - 1)\ %\ n$;
- 从环中移除该索引;
- 缩小环的周长。
- 返回值:返回仅剩的数字。
1 | public int lastRemaining(int n, int m) { |
- 时间复杂度: $O(n^2)$ ,以 $O(1)$ 定位到删除位置,然后移动元素 $O(n)$ ,需要循环 $n$ 次。
- 空间复杂度: $O(n)$,用于存储约瑟夫环。
Solution 2 - 数学反演
首先以 $m=2$ 为例来推理这个问题,对于 $m \ne 2$ 的情况,之后将会给出一个具有一般性的解法。
设 $f(n)$ 为在有 $n$ 个人时生还者的位置(最终的生还者只会有一个人)。走完一圈之后,所以偶数号(假设$m=2$)的人被杀。则在第二圈,新的编号为 $2、4、\dots$ 的人被杀,就像没有第一圈时一样。
如过一开始有偶数个人,则第二圈时位置为 $x$ 的人一开始在 $2x-1$ 的位置,因此位置为 $f(2n)$ 的人的开始时的位置为 $2f(n)-1$ ,递推公式为:
$$
f(2n)=2f(n)-1 \tag{1}
$$
如果一开始有奇数个人,则走了一圈以后,最终是号码为 $1$ 的人被杀。于是同样地,再走第二圈时,新的编号为 $2、4、\dots$ 的人被杀,等等。在这种情况下,位置为 $x$ 的人原先位置为 $2x+1$,递推公式为:
$$
f(2n+1)=2f(n)+1 \tag{2}
$$
如果把 $n$ 和 $f(n)$ 的值列成表,可以看出这样一个规律:
1 | n 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
从中可以看出,$f(n)$ 是一个递增的奇数数列,每当 $n$ 为 $2$ 的幂时,便重新从 $f(n)=1$ 开始。因此,如果选择 $m、l$ ,使得 $n=2^m+l$ 且 $0\le l \le 2^m$,那么 $f(n)=2l+1$。其中 $2^m$ 是不超过 $n$ 的最大幂, $l$ 是留下的数。上面代码块中的值满足这个方程,下面给出一个定理:
$$
如果\ n=2^m+l \ 且\ 0 \le l < 2^m,\ 则\ f(n)=2l + 1.
$$
一般情况下,考虑生还者的号码从 $n-1$ 到的 $n$ 变化, 可以得到以下的递推公式(编号从 $0$ 开始):
$$
f(n,k)=(f(n-1,k)+k)\ mod\ n,\quad f(1,k)=0
$$
1 | // 非递归 |
- 时间复杂度:$O(n)$。
- 空间复杂度:非递归版本 $O(1)$,递归栈可能需要 $O(n)$。
63. 股票的最大利润
题目描述
假设把某股票的价格按照时间先后顺序存储在数组中,请问买卖该股票一次可能获得的最大利润是多少?
1 | 输入: [7,1,5,3,6,4] |
Solution - 动态规划
状态定义:设动态规划列表为 $dp$, $dp[i]$ 代表以 $prices[i]$ 为结尾的子数组的最大利润,即到第 $i$ 天为止的最大利润。
状态转移方程:由于题目限定了一只股票只能买卖一次,因此前 $i$ 日的最大利润等于前 $i-1$ 日的最大利润 $dp[i-1]$ 和第 $i$ 日卖出股票后的利润之中的较大值(此时需要一个变量保存 $0..i-1$ 中的最小值),即:
$$
dp[i] = Math.max(dp[i-1], prices[i] - minCost)
$$1
2
3
4
5
6
7
8public int maxProfit(int[] prices) {
int cost = Integer.MAX_VALUE, profit = Integer.MIN_VALUE;
for (int price : prices) {
cost = Math.min(cost, price);
profit = Math.max(profit, price - cost);
}
return profit;
}时间复杂度:$O(n)$,扫描了一遍数组。
空间间复杂度:$O(1)$,只用到了两个变量。
64. 求 1+2+…+n
题目描述
求 $1+2+\cdots + n$ ,要求不能使用 $\times, \div, for, while, if-else, switch-case, A ? B : C$ 等关键字及三元运算符。
Solution - 逻辑短路
求从 $1$ 到 $n$ 的和通常有三种方式:
- 等差数列的求和公式:此时显然要用到乘法,简单来说不可取,但是有种方法叫做位运算快速乘可以实现
$$
\sum_{i = 1}^n i = \frac{n\times (n+1)}{2}
$$
- 迭代:需要用到 $if、for$ ,不可取。
1 | public int sumNums(int n) { |
- 递归:但是这样有三元运算符,也可以认为是 $if-else$,简单来看不可取,但是可以利用位运算的短路效应实现 $if-else$ 的功能。
1 | public int sumNums(int n) { |
所以上面方法可以改造为
1 | public int sumNums(int n) { |
- 时间复杂度:$O(n)$,需要开启 $n$ 个递归函数。
- 空间间复杂度:$O(n)$,递归深度达到 $n$。
65. 不用加减乘除做加法
写一个函数,求两个整数之和,要求在函数体内不得使用 “+”、“-”、“*”、“/” 四则运算符号。
1 | a, b 均可能是负数或 0 |
Solution - 位运算
设两个加数二进制表示分别为 $a, b$, 其和为 $s$,$a(i)$ 表示 $a$ 的第 $i$ 位,则分为以下四种情况:
| $a(i)$ | $b(i)$ | 无进位和 $n(i)$ | 进位 $c(i+1)$ |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
| 0 | 1 | 1 | 0 |
| 1 | 0 | 1 | 0 |
| 1 | 1 | 0 | 1 |
观察发现两个规律:
- 无进位和结果 = 异或结果,即 $n = a \oplus b$;
- 进位结果 = 与运算左移一位结果,即 $c = a & b << 1$。
所以 $s = a + b => s = n + c$,循环求 $n、c$ ,直至进位 $c=0$ ,此时 $s=n$ ,返回 $n$ 即可。
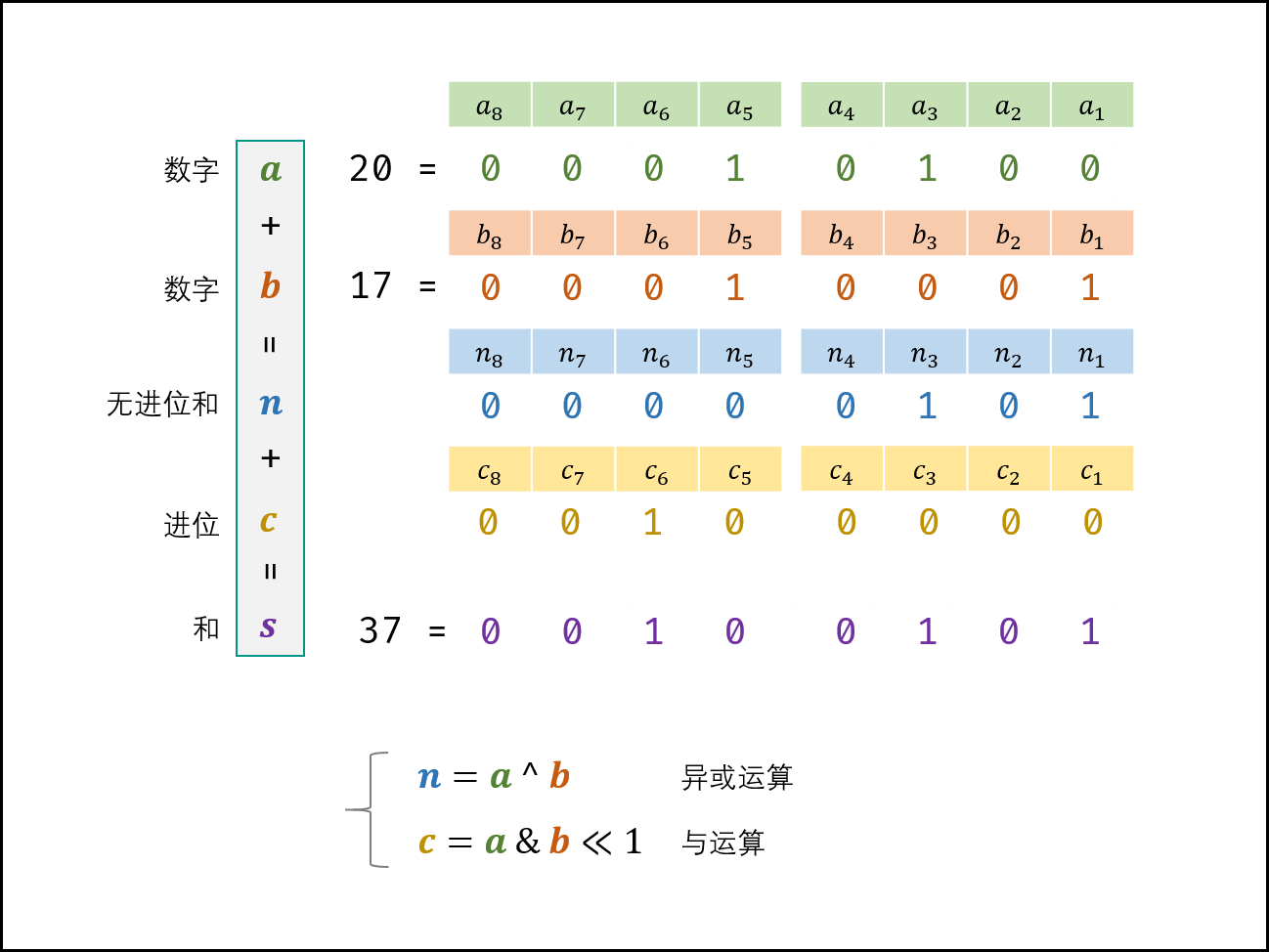
1 | public int add(int a, int b) { |
- 时间复杂度:$O(1)$,最多循环 $32$ 次,每次循环中操作 $O(1)$。
- 空间间复杂度:$O(1)$,常数个额外空间。
66. 构建乘积数组
题目描述
给定一个数组 $A[0,1,…,n-1]$,请构建一个数组 $B[0,1,…,n-1]$,其中 $B$ 中的元素 $B[i]=A[0]×A[1]×…×A[i-1]×A[i+1]×…×A[n-1]$。不能使用除法。
1 | 输入: [1,2,3,4,5] |
Solution
本题难点在于不能使用除法,观察 $B[i]$ 的定义发现缺少一项,即 $A[i]$,但是其实我们可以将 $A[i]$ 也乘入其中,如果 $A[i] = 1$ 的话。基本思路就是使用 $A[i] = 1$ 这个桥梁,将 $B[i]$ 的乘积表达式分成两部分,即 $A[i]$ 左侧与 $A[i]$ 右侧。这个时候可以考虑建立一个 $n \times n$ 的方阵,且其主对角线为 $1$。
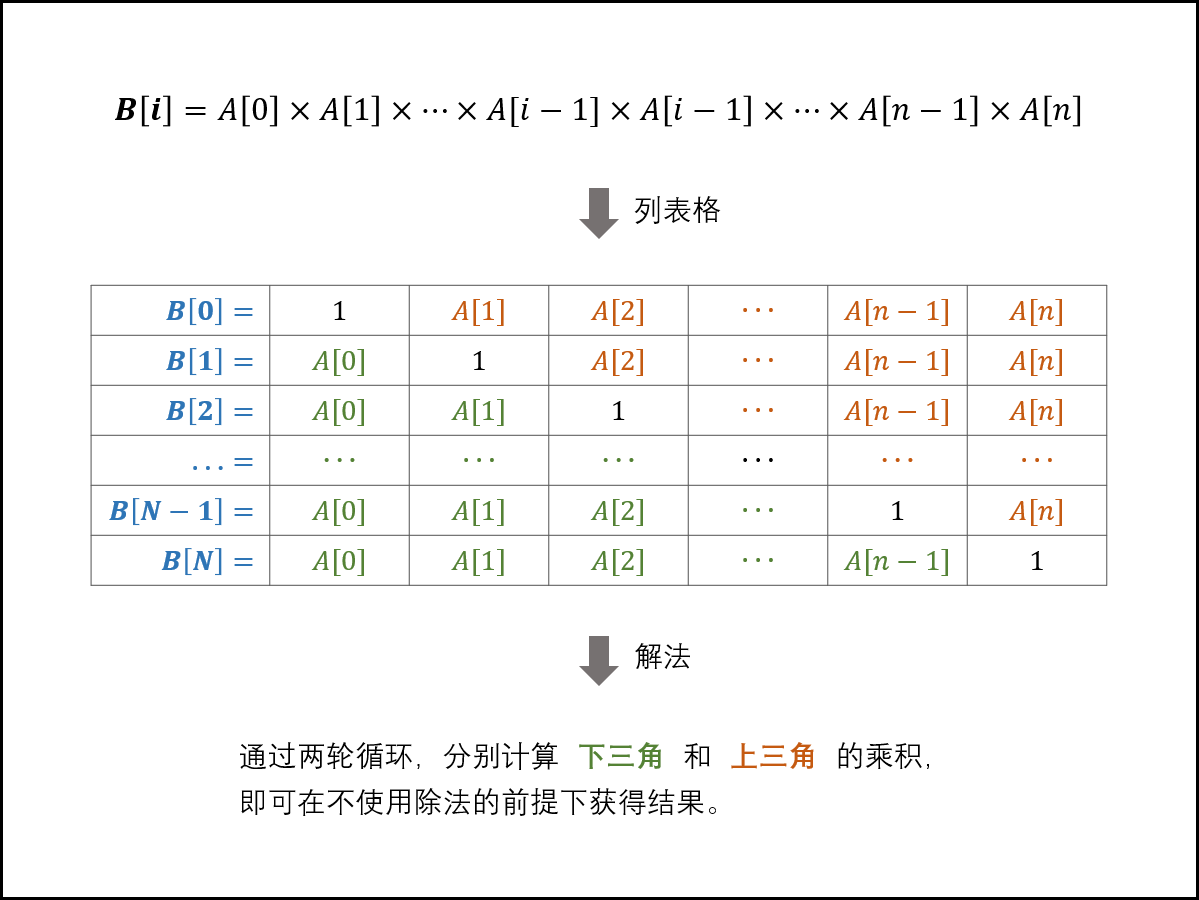
算法流程
- 初始化:数组 $B[0] = 1$,中间变量 $tmp = 1$;
- 分别计算下三角各同行元素乘积,存入 $B[i]$;
- 将上三角同行($i$ 行)元素与 $B[i]$ 相乘,并更新 $B[i]$ 为此结果;
- 返回 $B$。
1 | public int[] constructArr(int[] a) { |
- 时间复杂度:$O(n)$,需要扫描两次数组。
- 空间间复杂度:$O(1)$,中间变量 $tmp$。
67. 把字符串转换成整数
题目描述
写一个函数 StrToInt(),实现把字符串转换成整数这个功能。不能使用 atoi 或者其他类似的库函数。
该函数具有如下功能:
根据需要丢弃无用的开头空格字符,直到寻找到第一个非空格的字符为止;
当寻找到的第一个非空字符为正或者负号时,则将该符号与之后面尽可能多的连续数字组合起来,作为该连续数字的正负号;
当寻找到的第一个非空字符是数字,则直接将其与之后连续的数字字符组合起来,形成整数。
该字符串除了有效的整数部分之后也可能会存在多余的字符,这些字符可以被忽略,它们对于函数不应该造成影响。
- 假如该字符串中的第一个非空格字符不是一个有效整数字符、字符串为空或字符串仅包含空白字符时,函数不需要进行转换;
- 在任何情况下,若函数不能进行有效的转换时,返回 $0$;
- 数字转换范围为:$[-2^{31}, 2^{31}-1]$,如果超过这个范围则返回
Integer.MIN_VALUE或Integer.MAX_VALUE。 - 本题与主站第 8 题相同
Solution
根据题意,有以下几种情况需要考虑:
- 左起第一个符号或数字位之前为空格:直接删除即可;
- 符号位:可能为 $+-$、或者无符号,保存一个变量代表符号位,$-1$ 代表 $-$ 号,$1$ 代表 $+$ 或无符号;
- 非数字字符:直接返回,因为已经不是数字了,例如 $123x$ 或者 $-x123$;
- 数字字符:从左向右遍历时,设当前位的字符为 $c$ ,当前位的字符对应的数字为 $x$ ,当前位置时的结果为 $res$。
- 字符转数字:将此数字的 $ASCII$ 码与 $0$ 的 $ASCII$ 码相减,获得该字符的数值表示 $x = ascii(c) - ascii(0)$;
- 字符拼接:$res = res \times 10 + x$。
数字越界处理:题目要求返回的值的范围在 $[-2^{31}, 2^{31}-1]$,观察 $-2147483648$ 与 $2147483647$ 可以发现它们的除去符号位的前九位都是相同的,即 $boundry = 214748364$,只有最后一位分别是 $7、8$ ,而且又因为它们的符号相反,所以在符号为 $-$ 时可以判断最后一个字符是否小于 $7$,而符号为正时的判断也是最后一位是否 $< 7$。
1 | public int strToInt(String str) { |
- 时间复杂度:$O(n)$,需要扫描一遍字符数组。
- 空间间复杂度:$O(n)$,存储字符数组。
68(🌲) - I. 二叉搜索树的最近公共祖先
题目描述
给定一棵二叉树, 找到该树中两个指定节点的最近公共祖先。
最近公共祖先的定义为:“对于有根树 $T$ 的两个节点 $p、q$,最近公共祖先表示为一个节点 $x$,满足 $x$ 是 $p、q$ 的祖先且 $x$ 的深度尽可能大(一个节点也可以是它自己的祖先)。”
例如,给定如下二叉搜索树: $root = [6,2,8,0,4,7,9,null,null,3,5]$
1 | 输入: root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 8 |
解析
祖先的定义:若节点 $p$ 在节点 $root$ 的左/右子树中,或 $p = root$,则称 $root$ 是 $p$ 的祖先。
最近公共祖先的定义: 设节点 $root$ 为节点 $p、q$ 的某公共祖先,若其左子节点 $root.left$ 和右子节点都不是 $p、q$ 的公共祖先,则称 $root$ 是最近公共祖先。
因此:若 $root$ 是 $p、q$ 的最近公共祖先,则只能为以下情况之一:
- $p、q$ 在 $root$ 的子树中,且分列 $root$ 的左右两侧;
- $p = root$,且 $q$ 在 $root$ 左子树或右子树中;
- $q = root$,且 $p$ 在 $root$ 左子树或右子树中。
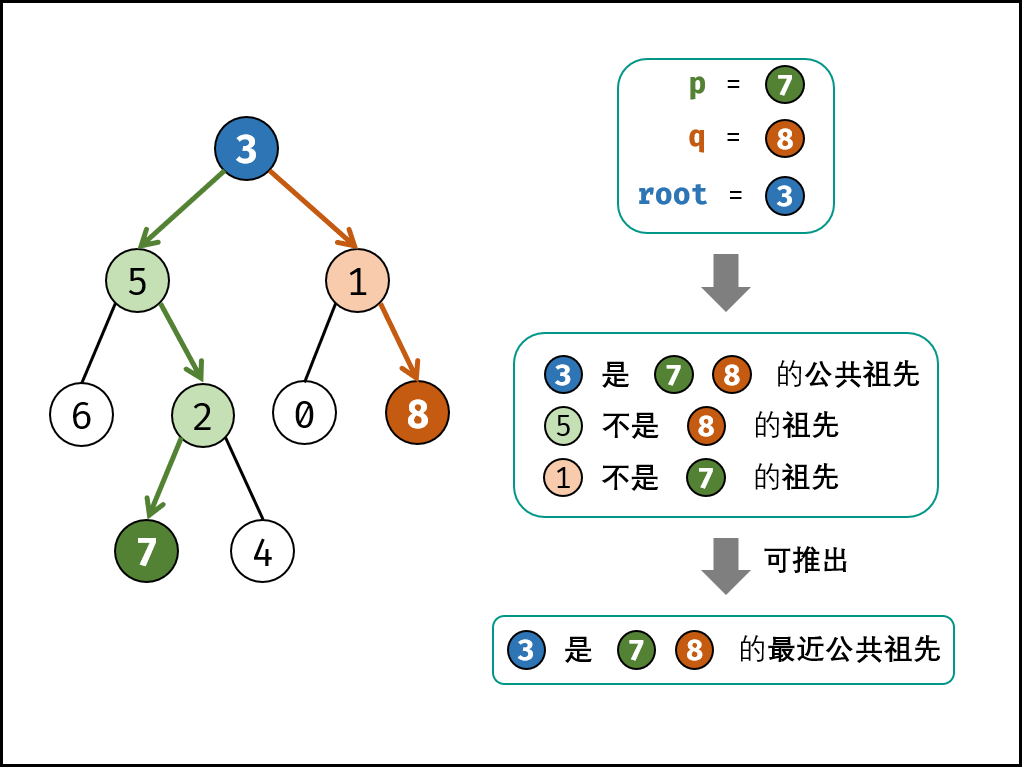
1 | 两个重要条件 |
Solution 1 - 迭代
- 循环搜索:当结点 $root$ 为空时跳出
- 当 $p、q$ 都在 $root$ 的右子树中,则到 $root.right$ 遍历;
- 当 $p、q$ 都在 $root$ 的左子树中,则到 $root.left$ 遍历;
- 否则,说明找到了最近公共祖先,跳出。
- 返回值:最近公共祖先 $root$。
1 | public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) { |
- 时间复杂度:$O(n)$, 其中 $n$ 为二叉树结点个数。每循环一轮排除掉一层,二叉搜索树的最坏情况为退化为链表。
- 空间复杂度:$O(1)$。
Solution 2 - 递归
- 递推工作:
- 当 $p、q$ 都在 $root$ 的右子树中,则开启递归 $root.right$ 并返回。
- 否则,当 $p、q$ 都在 $root$ 的左子树中,则开启递归 $root.left$ 并返回。
- 返回值:最近公共祖先 $root$。
1 | public TreeNode lowestCommandAncestor(TreeNode root, TreeNode p, TreeNode q) { |
- 时间复杂度:$O(n)$。
- 空间复杂度:$O(n)$,最坏情况下,树退化为链表,递归深度达到 $n$。
68(🌲) - II. 二叉树的最近公共祖先
题目描述
给定一棵二叉树, 找到该树中两个指定节点的最近公共祖先。
最近公共祖先的定义为:“对于有根树 $T$ 的两个节点 $p、q$,最近公共祖先表示为一个节点 $x$,满足 $x$ 是 $p、q$ 的祖先且 $x$ 的深度尽可能大(一个节点也可以是它自己的祖先)。”
例如,给定如下二叉树: $root = [3,5,1,6,2,0,8,null,null,7,4]$。
1 | Case 1: |
Solution - 后序遍历
最近公共祖先的定义: 设节点 $root$ 为结点 $p、q$ 的某公共祖先,若其左子节点 $root.left$ 和右子节点 $root.right$ 都不是 $p、q$ 的公共祖先,则称 $root$ 为最近公共祖先。且仅有以下三种情况:
- $p、q$ 在 $root$ 的子树中,且分列 $root$ 两侧;
- $p = root$,且 $q$ 在 $root$ 左子树或右子树中;
- $q = root$,且 $p$ 在 $root$ 左子树或右子树中。
使用递归对二叉树进行后序遍历,当遇到结点 $p$ 或 $q$ 时返回,自底向上回溯,当结点 $p、q$ 在结点 $root$ 的两侧时,结点 $root$ 即为最近公共祖先,向上返回 $root$。
递归解析:
终止条件
- 越过叶结点,返回 $null$。
root == p || root == q,返回root.
递推工作
- 开启递归左子结点,返回值记为
left。 - 开启递归右子结点,返回值记为
right。
- 开启递归左子结点,返回值记为
返回值: 根据
left和right,可具体分为四种情况left == null || right == null:说明root的左右子树都不包含p、q,返回null;left != null || right != null: 说明p、q分列root两侧,因此root为最近公共祖先,返回root;left == null && right != null:说明p、q都不在root的左子树中,直接返回right。具体又可分为两种情况:p、q其中一个在root的右子树中,也就是p = root || q == root,此时假设right指向p;p、q两结点都在root的右子树中,此时的right指向最近公共祖先结点。
left != null && right == null: 与上种情况类似。
1 | public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) { |
- 时间复杂度:$O(n)$, 最坏情况下需要遍历所有的树结点。
- 空间复杂度:$O(n)$, 最坏情况下,递归深度达到 $n$。