常用类库与技巧
1 异常处理
1.1 异常处理机制
- 异常处理机制主要回答了三个问题
- What:异常类型回答了什么被抛出
- Where:异常堆栈跟踪回答了在哪抛出
- Why:异常信息回答了为什么被抛出
- Java 异常体系

RuntimeException: 不可预知的,程序应当自行避免非 RuntimeException:可预知的,从编译器校验的异常- 从概念角度解析 Java 的异常处理机制
- Error:程序无法处理的系统错误,编译器不做检查
- Exception:程序可以处理的异常,捕获后可能恢复
- 总结:前者是程序无法处理的错误,后者是可以处理的异常
- 从责任角度解析 Java 的异常处理机制
Error属于 JVM 需要承担的责任RuntimeException是程序应该承担的责任Checked Exception可检查异常是 Java 编译器应该负担的责任
1.2 常见 Error 及 Exception
RuntimeExceptionNullPointerException:空指针引用异常ClassCastException:类型强制转换异常IllegalArgumentExceptionIndexOutOfBoundsExceptionNumberFormatException
- 非
RuntimeExceptionClassNotFoundExceptionIOException
ErrorNoClassDefFoundErrorStackOverflowError深度递归导致栈被耗尽而抛出的异常OutOfMemoryError内存溢出
1.3 异常处理方法
- 抛出异常:创建异常对象,交由运行时系统处理
- 捕获异常:寻找合适的异常处理器处理异常,否则终止运行
1.4 异常处理原则
- 具体明确:抛出的异常应能通过类名和
message准确说明异常的类型和产生异常的原因 - 提早抛出:应尽可能早的发现并抛出异常,便于精确定位问题
- 延迟捕获:异常的捕获和处理应尽可能延迟,让掌握更多信息的作用域来处理异常
1.5 高效主流的异常处理框架
在用户看来,应用系统发生的所有异常都是应用系统内部的异常
- 设计一个通用的继承自
RuntimeException的异常来统一处理 - 其余异常都统一转移为上述异常
AppException - 在
catch之后,抛出上述异常的子类,并提供足以定位的信息 - 由前端接收
AppException做统一处理
1.6 try-catch 的性能
- Java异常处理消耗性能的地方
try-catch块影响 JVM 的优化- 异常对象实例需要保存堆栈快照等信息,开销较大
2 集合框架
- 数据结构考点
- 数组和链表的区别
- 链表的操作,如反转,链表环路检测,双向链表,循环链表相关操作
- 队列,栈的应用
- 二叉树的遍历方式及其递归和非递归的实现
- 红黑树的旋转
- 算法考点
- 内部排序:如递归排序,交换排序(冒泡,快排),选择排序,插入排序
- 外部排序:应掌握如何利用有限的内存配合海量的外部存储来处理超大的数据集,
- 考点扩展
- 哪些排序是不稳定的,稳定意味着什么?
- 不同数据集,各种排序最好或最坏的情况
- 如何优化算法
2.1 集合框架
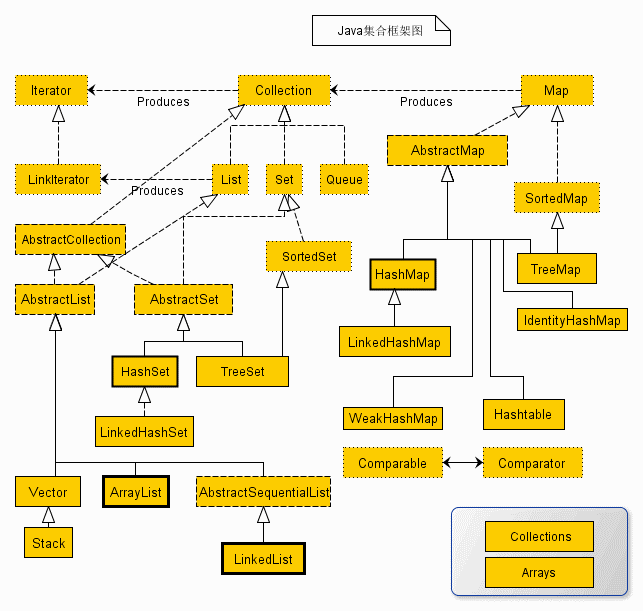
2.2 集合之 List 与 Set

2.3 集合之 Map
- 见文章
HashMap
3 J.U.C 知识点梳理
java.util.concurrent : 提供了并发编程的解决方案
CAS是java.util.concurrent.atomic包的基础AQS是java.util.concurrent.locks包以及一些常用类如Semophore、ReentrantLock等类的基础
3.1 包的分类
- 线程执行器:
executor - 锁:
locks - 原子变量类:
atomic - 并发工具类 :
tools - 并发集合类:
collections
3.2 并发工具类
- 闭锁:
CountDownLatch- 让主线程等待一组事件发生后继续执行
- 栅栏:
CyclicBarrier- 阻塞当前线程,等待其它线程,所有线程必须同时到达栅栏的位置后才能继续执行
- 所有线程到达栅栏处,可以触发执行另外一个预先设置的线程
- 信号量:
Semaphore- 控制某个资源可被同时访问的线程个数
- 交换器:
Exchanger- 两个线程到达同步点后,相互交换数据
4 IO
4.1 BIO
- BIO - InputStream、OutputStream、Reader 和 Writer

4.2 NIO
NonBlock-IO:构建多路复用的,同步非阻塞 IO

4.2.1 NIO的核心
Channels 通道
- FileChannel
- DatagramChannel
- SocketChannel
- ServerSocketChannel
Buffers 缓冲区
- ByteBuffer
- CharBuffer
- DoubleBuffer
- FloatBuffer
- IntBuffer
- LongBuffer
- LongBuffer
- ShortBuffer
- MappedByteBuffer
Selectors 选择器 NIO有、而IO没有
选择器用于使用单个线程处理多个通道。因此,它需要较少的线程来处理这些通道。线程之间的切换对于操作系统来说是昂贵的。 因此,为了提高系统效率选择器是有用的。

4.2.2 NIO读写数据方式
通常来说NIO中的所有IO都是从 Channel(通道) 开始的。
- 从通道进行数据读取 :创建一个缓冲区,然后请求通道读取数据。
- 从通道进行数据写入 :创建一个缓冲区,填充数据,并要求通道写入数据。

4.2.3 IO 多路复用
调用系统级别的 select/poll/epoll

| 名称 | 描述 | 效率问题 | 消息传递方式 |
|---|---|---|---|
| select | 单个进程所能打开的最大连接数由 FD_SETSIZE 宏定义 |
因为每次调用时都会对连接进行线性遍历,所以随着 FD 的增加会造成遍历速度的线性下降的性能问题 | 内核需要将消息传递到用户空间,需要内核的拷贝动作 |
| poll | 本质上与select没有区别,但是它没有最大连接数的限制,原因是它是基于链表来存储的 | 同上 | 同上 |
| epoll | 虽然连接数有上限,但是很大,1G内存的机器上可以打开10万左右连接 | 由于epoll是根据每个FD上的 callback 函数来实现的,只有活跃的 socket 才会主动调用callback,所以性能与socket 的活跃程度有关 |
通过内核和用户空间共享一块内存来实现,性能较高 |
4.3 AIO
Asynchronous IO: 基于事件和回调机制

AIO如何进一步处理结果:
- 基于回调:实现
CompletionHandler接口,调用时触发回调函数 - 返回
Future: 通过isDone()查看是否准备好,通过get()等待返回数据
4.2 BIO、NIO、AIO对比
| 属性、模型 | BIO | NIO | AIO |
|---|---|---|---|
| blocking | 阻塞并同步 | 非阻塞但同步 | 非阻塞并异步 |
| 线程数 | 1:1 | 1:N | 0:N |
| 复杂度 | 简单 | 较复杂 | 复杂 |
| 吞吐量 | 低 | 高 | 高 |