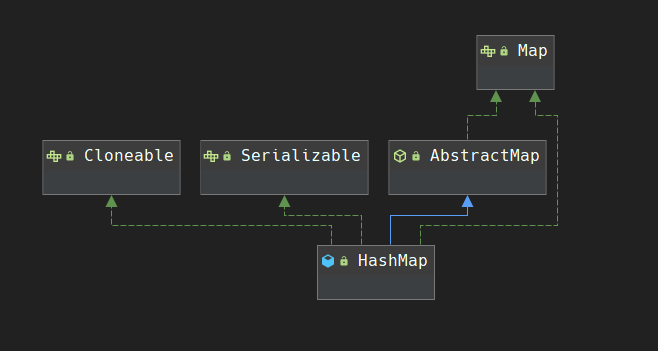
HashMap
HashMap
Map简介
Map中可以说是Java面试中最热门的考点了,提起Map能想到什么呢?HashMap,LinkedHashMap,ConcurrentHashMap,ConcurrentSkipListMap,ConcurrentNavigableMap,ThreadLocalMap,这是JDK为我们提供的。Spring中还有getBean("xxx")…现在先专注于HashMap吧,以后陆续把这些欠下的知识给补上。
HashMap基础
构造函数(4种)
1 | public HashMap() { |
存储无序
1 | public static void main(String[] args) { |
从输出结果可以看出,HashMap存储与打印的顺序不是一致的,也就是HashMap存储数据不是按序存储的,如果需要按序存储可以选择LinkedHashMap,TreeMap,其中LinkedHashMap是用双向链表来保持有序的,而TreeMap则是用红黑树保持有序的。
重要变量
1 | /** 默认初始容量 = 16, 比如为 2 的幂 **/ |
关于为什么要把树化阈值设置为 $8$. 可以参考 阿里面试题:为什么Map桶中个数超过8才转为红黑树,但是个人更推荐看
HsahMap源码中的最前面的注释Implementation notes.,刚才读了一下,感觉很有必要专门写几篇读前言注释的文章了,先大致记载一下刚才获取到的对我而言的新知识。
TreeNode所占空间近乎Node两倍,在此就考虑到了空间与时间。- 转化成红黑树时,默认按照
key的hashCode()结果进行排序,也可以自定义比较器。 - 在
random hashCodes情况下,bucket中的nodes服从 泊松分布,平均情况下为
$$
p=\frac{0.5^k}{k!}e^{-0.5}, k=0,1,2,\cdots,n
$$
$k$ 的意思是在忽略方差的情况下,链表的长度( $Node$ 的个数),p代表链表长度为 $k$ 时的概率。下面为链表长度出现 $k$ 从 $1$ 到 $8$ 时的概率
1 | * 0: 0.60653066 |
也就是说,在同一个
bucket发生 $8$ 次以上碰撞的概率已经小于千万分之一,所以不应该轻易认为链表转化为红黑树是很常见的事情。在数据量达到千万或者亿级以上的时候(还记得哈希表的MAXIMUM_CAPACITY = 1 << 30吗?)可能才会偶尔出现,而这个时候哈希表的效率就显得尤为重要。
网上有很多博客都在强调 $O(n)$ 与 $O(\lg n)$ 的区别,当结点数量为 $8$ 时,
- 平均情况下:链表查找长度为 $n/2=4$ ,而红黑树的查找长度为 $\log_2 n = 3$,差别好像并不是很大。
- 最坏情况下:链表查找长度为 $8$,红黑树为 $3$, 好像已经隐隐接近 $3$ 倍,省下了 $5$ 个查找单位时间,但是这种情况出现的概率呢?千万分之六.
存储结构及冲突解决方案
Java8之前:数组加链表Java8及之后:数组+链表+红黑树 (当链表的长度大于 $8$ 时转化为红黑树,当红黑树的结点个数小于 $6$ 时再转化为链表, 这样做是为了保证在最坏查找情况下HashMap的查找时间复杂度为 $O(\lg n)$,而不是 $O(n)$ )。- 红黑树复习
- 其他解决冲突的方法:开放定址法,线性探测再散列、平方探测法、再哈希法、双散列函数法…
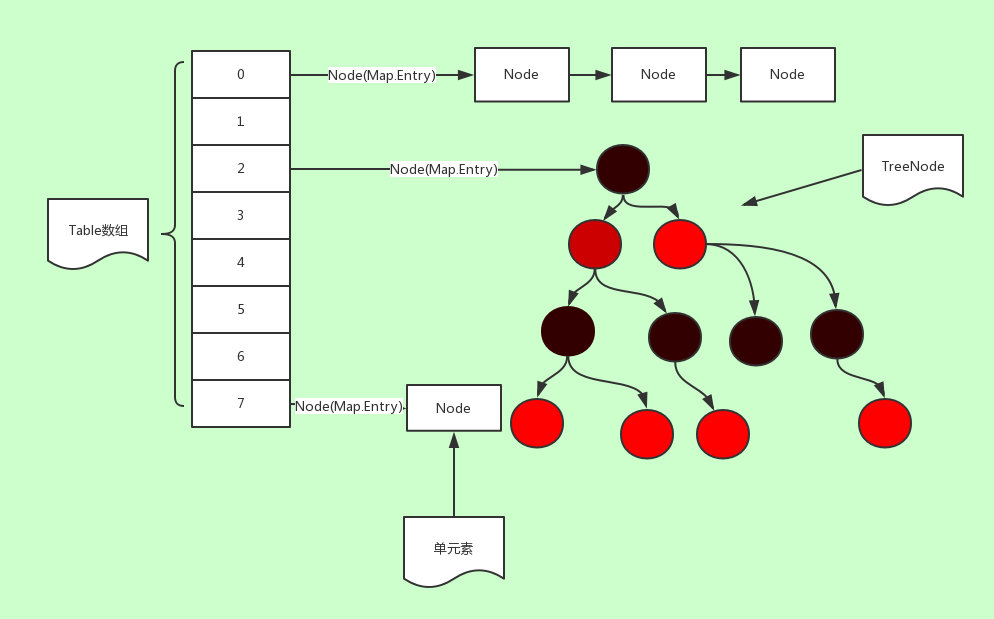
内部类
从源码可知,HashMap类中有一个实现了 Map.Entry<> 接口的静态类 static class Node<K,V> implements Map.Entry<K,V>,有一个非常重要的字段定义为 transient Node<K,V>[] table; 即哈希桶数组,也就是上图中的Table数组。
1 | static class Node<K,V> implements Map.Entry<K,V> { |
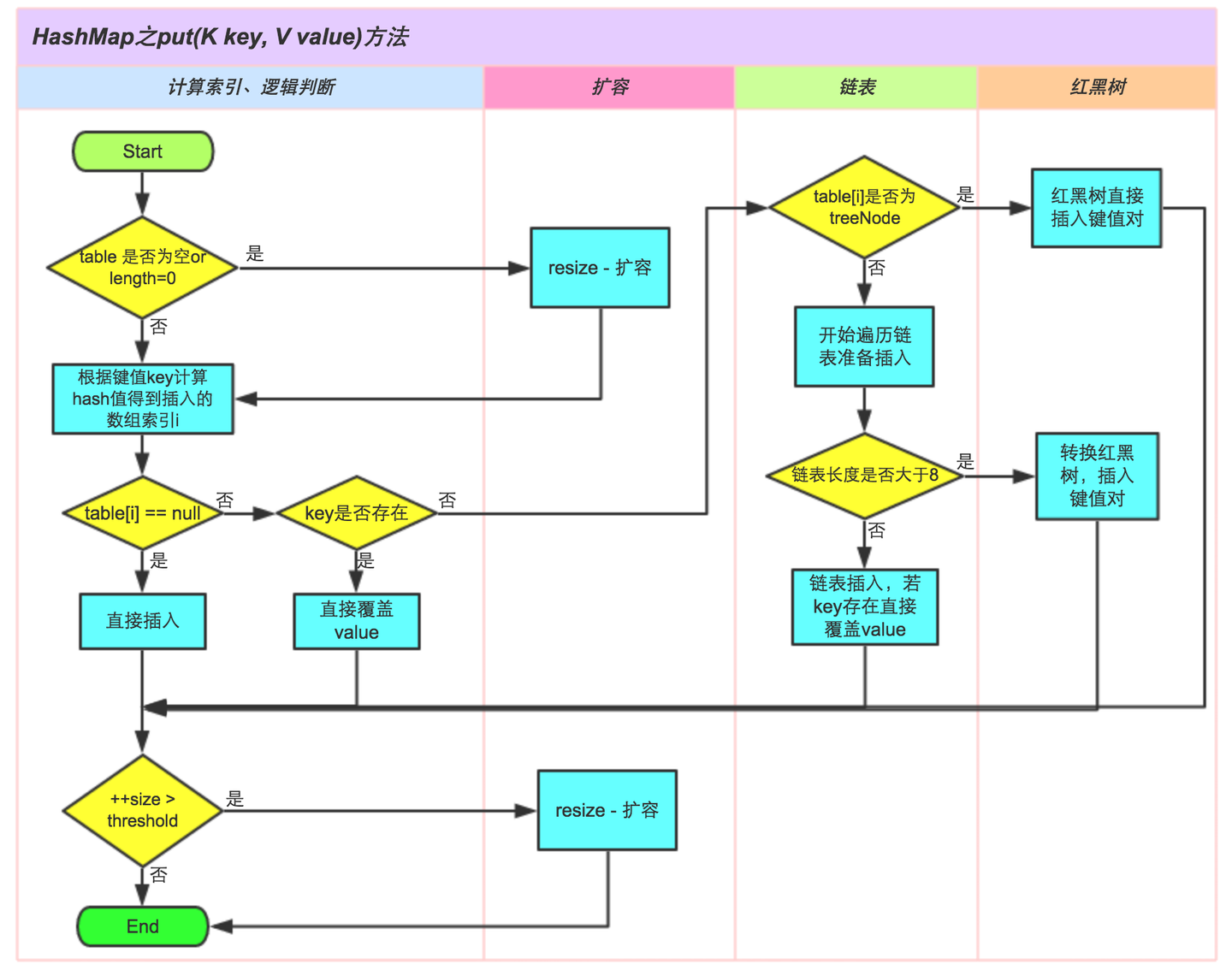
put() 方法
1 | map.put("Banana", "香蕉"); |
put()方法的逻辑- 如果
HashMap未被初始化过,则初始化 - 对
key求Hash值,然后计算下标 - 如果没有碰撞,则直接放入桶中
- 如果碰撞了,以链表的方式链接到后边
- 如果链表长度
>= TREEIFY_THRESHOLD - 1,并且table >= MIN_TREEIFY_CAPACITY将链表转化为红黑树,否则可能只是扩容。 - 如果红黑树结点小于 $6$ ,将红黑树转化为链表
- 如果结点已经存在就替换旧值
- 如果初始桶装满了(容量 $16 \times 0.75 = 12$,就需要扩容
resize()(扩容 $2$ 倍)
- 如果
- 如何有效减少碰撞?
- 扰动函数:促使元素位置分布均匀,减少碰撞几率
- 使用
final对象,并采用合适的equals()和hashCode()方法
1 | public V put(K key, V value) { |
确定索引位置
1 | static final int hash(Object key) { //jdk1.8 & jdk1.7 |
HashMap怎么保证底层数组的长度总是 $2^n$ ?试一试就知道了。
1 | static final int tableSizeFor(int cap) { |
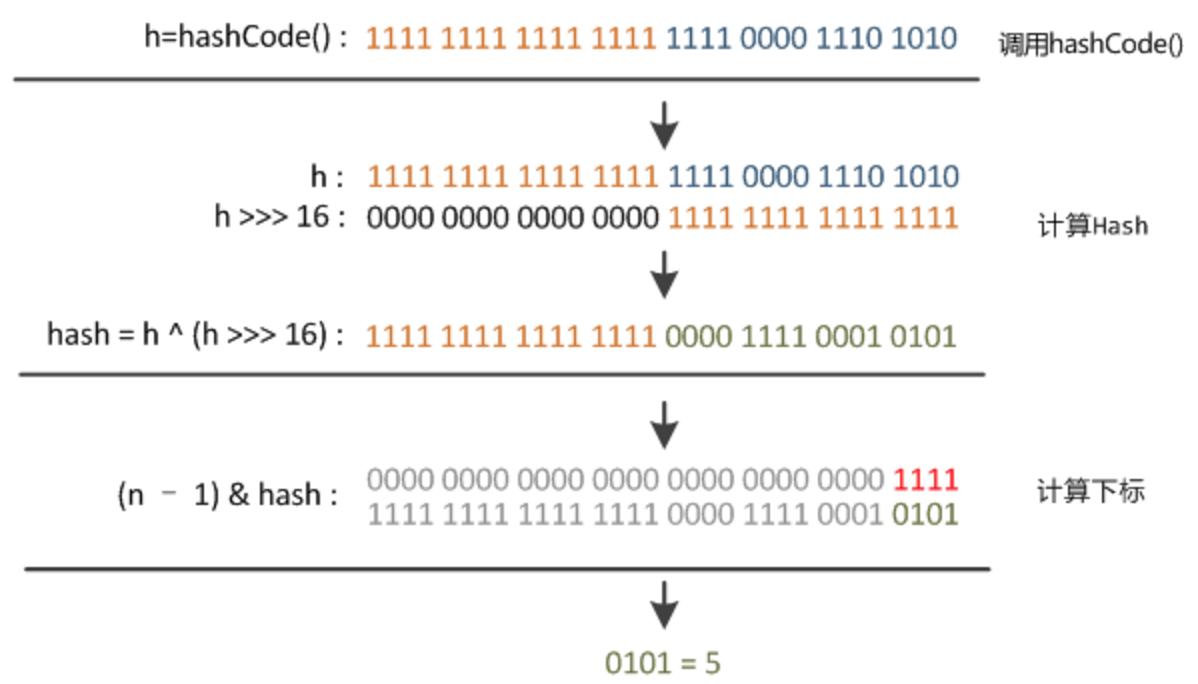
这里的Hash算法本质上就是三步:取key的hashCode值、高位运算、取模运算。
在JDK1.8的实现中,优化了高位运算的算法,通过hashCode()的高 $16$ 位异或低 $16$ 位实现的:(h = k.hashCode()) ^ (h >>> 16),主要是从速度、功效、质量来考虑的,这么做可以在数组 table.length 比较小的时候,也能保证考虑高低位都参与到Hash的计算中,同时不会有太大的开销。
扩容 resize()
在理解Hash和扩容流程之前,我们得先了解下 HashMap 的几个字段。从 HashMap 的默认构造函数源码可知,构造函数就是对下面几个字段进行初始化,源码如下:
1 | public class HashMap<K,V> extends AbstractMap<K,V> |
扩容(resize)就是重新计算容量,向HashMap对象里不停的添加元素,而HashMap对象内部的数组无法装载更多的元素时,对象就需要扩大数组的长度,以便能装入更多的元素。当然Java里的数组是无法自动扩容的,方法是使用一个新的数组代替已有的容量小的数组,将小容量数组中的元素复制到大容量数组里,并释放小容量数组。
分析下 resize 的源码,鉴于JDK1.8融入了红黑树,较复杂,为了便于理解仍然使用JDK1.7的代码,好理解一些,本质上区别不大,具体区别后文再说。
此部分内容大量参考- 美团技术团队知乎文章
1 | 1 void resize(int newCapacity) { //传入新的容量 |
这里就是使用一个容量更大的数组来代替已有的容量小的数组,transfer() 方法将原有Entry数组的元素拷贝到新的Entry数组里。
1 | 1 void transfer(Entry[] newTable) { |
newTable[i] 的引用赋给了 e.next,也就是使用了单链表的头插入方式,同一位置上新元素总会被放在链表的头部位置;这样先放在一个索引上的元素终会被放到Entry链的尾部(如果发生了hash冲突的话),这一点和JDK1.8有区别,下文详解。在旧数组中同一条Entry链上的元素,通过重新计算索引位置后,有可能被放到了新数组的不同位置上。
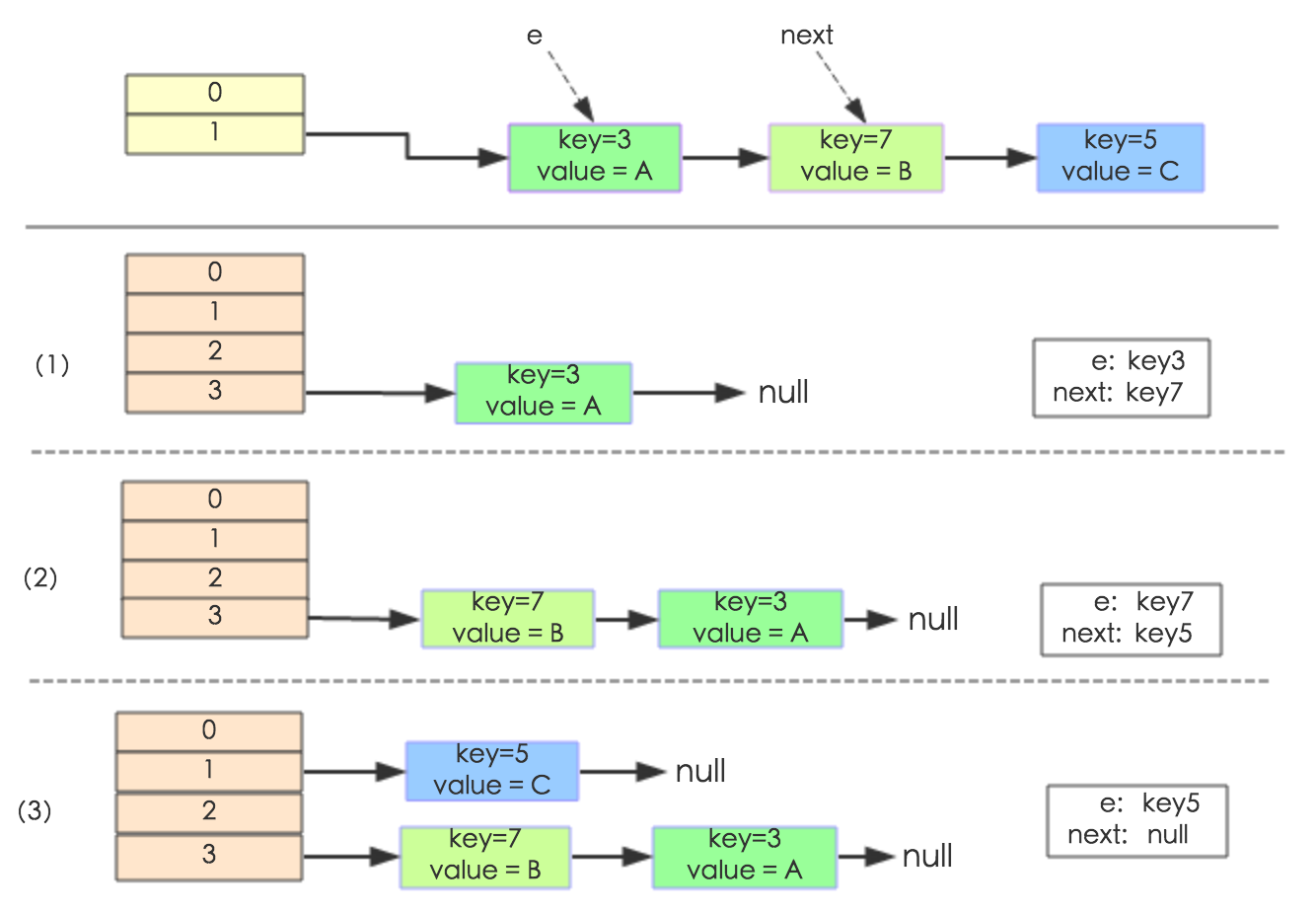
下面举个例子说明下扩容过程。假设了我们的hash算法就是简单的用 key mod table.size()。其中的哈希桶数组table的size = 2, 所以 key = 3、7、5,put顺序依次为 $ 5、7、3$。在 mod 2 以后都冲突在 table[1] 这里了。这里假设负载因子 loadFactor=1,即当键值对的实际大小 size 大于table 的实际大小时进行扩容。接下来的三个步骤是哈希桶数组 resize 成 $4$,然后所有的 $Node$ 重新 rehash 的过程。
下面我们讲解下JDK1.8做了哪些优化。经过观测可以发现,我们使用的是 $2$ 次幂的扩展(指长度扩为原来 $2$ 倍),所以,元素的位置要么是在原位置,要么是在原位置再移动 $2$ 次幂的位置。看下图可以明白这句话的意思,$n$ 为 $table$ 的长度,
- 图$(a)$表示扩容前的
key1和key2两种key确定索引位置的示例 - 图$(b)$表示扩容后
key1和key2两种key确定索引位置的示例,其中hash1是key1对应的哈希与高位运算结果。
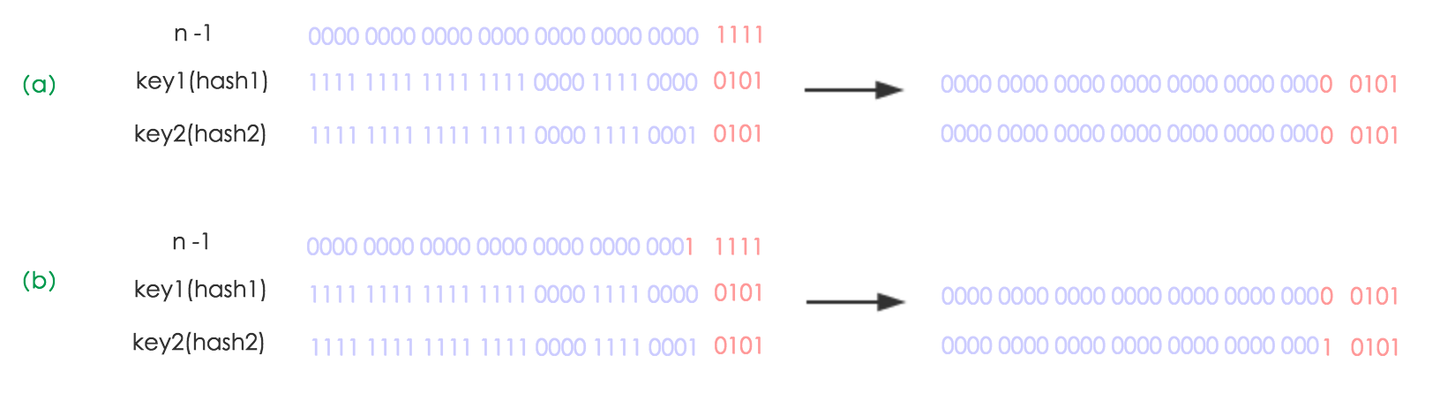
元素在重新计算hash之后,因为 $n$ 变为 $2$ 倍,那么 $n-1$ 的 $mask$ 范围在高位多 $1bit$ (红色),因此新的 $index$ 就会发生这样的变化:
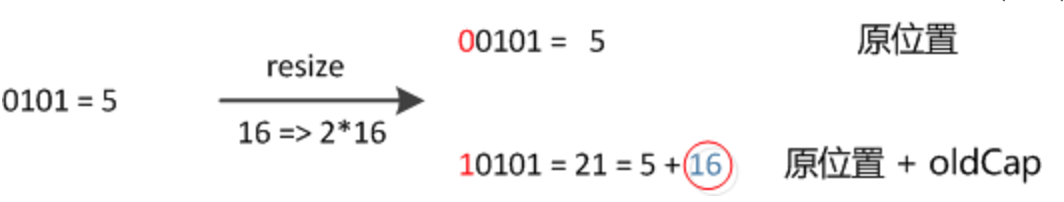
因此,我们在扩充 $HashMap$ 的时候,不需要像 $JDK1.7$ 的实现那样重新计算 $hash$,只需要看看原来的 $hash$ 值新增的那个 $bit$ 是 $1$ 还是 $0$ 就好了,是 $0$ 的话索引没变,是 $1$ 的话索引变成 原索引+oldCap,可以看看下图为 $16$ 扩充为 $32$ 的 $resize$ 示意图:
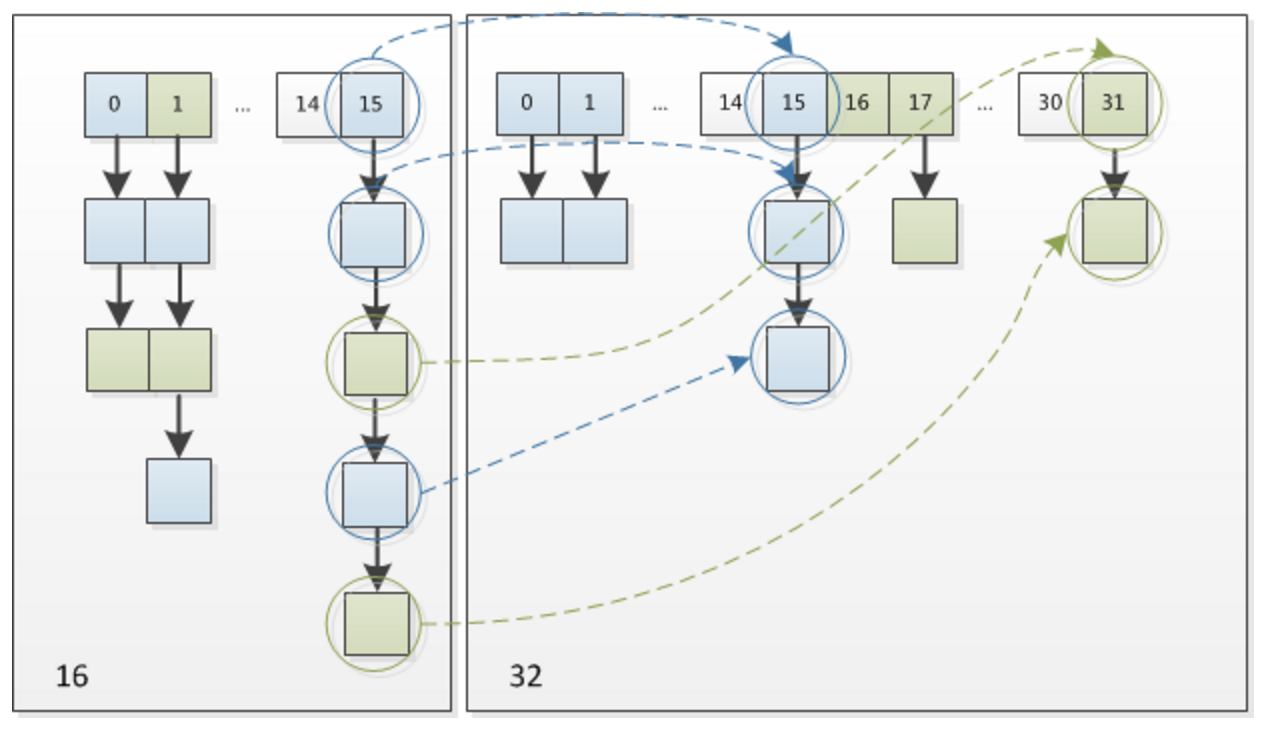
这个设计确实非常的巧妙,既省去了重新计算 $hash$ 值的时间,而且同时,由于新增的 $1bit$ 是 $0$ 还是 $1$ 可以认为是随机的,因此 $resize$ 的过程,均匀的把之前的冲突的节点分散到新的 $bucket$ 了。这一块就是 $JDK1.8$ 新增的优化点。有一点注意区别,$JDK1.7$中 $rehash$ 的时候,旧链表迁移新链表的时候,如果在新表的数组索引位置相同,则链表元素会倒置,但是从上图可以看出,$JDK1.8$ 不会倒置。有兴趣的同学可以研究下$JDK1.8$的 $resize$ 源码,写的很赞,如下:
1 | final Node<K,V>[] resize() { |
线程安全性
首先,说
HashMap是线程不安全的,并不仅仅是指循环链表的问题,而是在设计与实现上就没有考虑并发环境。
HashMap的设计目标是非并发环境下的简洁高效,并没有采取任何措施来保证put,remove以及其他操作的线程安全性,get操作的死循环问题只是线程不安全中最突出的代表。
1 | JDK 1.7 |
1 | 上面说到,HashMap会进行resize操作,在resize操作的时候会造成线程不安全。下面将举两个可能出现线程不安全的地方。 |
具体分析见:美团文章 - 线程安全性部分
解决办法:
Collections.synchronizedMap(): 加入了synchronized代码块java.util.concurrent.ConcurrentHashMap():CAS + synchronized使锁更细化
ConcurrentHashMap:put()方法的逻辑判断
Node[]数组是否初始化,没有则进行初始化操作通过
hash定位数组的索引下标,是否有Node结点,如果没有则使用CAS进行添加(链表的头结点) ,添加失败则进入下次循环.检查到内部正在扩容,就帮助它一起扩容
如果
f != null,则使用synchronized锁住f元素(链表/红黑树的头元素)4.1 如果是
Node(链表结构) 则执行链表的添加操作4.2 如果是
TreeNode(树形结构) 则执行树添加操作判断链表长度已经达到临界值 $8$(默认值,可修改),当结点数超过这个值就需要把链表转换为树结构。
ConcurrentHashMap: 需要注意的点size()方法和mappingCount()方法的异同,两者计算是否准确?- 多线程环境下如何进行扩容?
HashMap、Hashtable、ConcurrentHashMap区别
| 比较方面 | HashMap | Hashtable | ConcurrentHashMap |
|---|---|---|---|
| 是否线程安全 | 否 | 是 | 是 |
| 线程安全采用的方式 | 无 | 采用synchronized类锁,效率低 |
CAS + synchronized,锁住的只有当前操作的bucket,不影响其他线程对其他bucket的操作,效率高 |
| 数据结构 | 数组+链表+红黑树(链表长度超过8则转红黑树) | 数组+链表 | 数组+链表+红黑树(链表长度超过8则转红黑树) |
是否允许null键值 |
是 | 否 | 否 |
| 哈希地址算法 | (h=key.hashCode())^(h>>>16 |
key.hashCode() |
(h=key.hashCode())^(h>>>16)&0x7fffffff |
| 定位算法 | (n-1)&hash |
(hash&0x7fffffff)%n |
(n-1)&hash |
| 扩容算法 | 当键值对数量大于阈值,则容量扩容到原来的2倍 | 当键值对数量大于等于阈值,则容量扩容到原来的2倍+1 | 当键值对数量大于等于sizeCtl,单线程创建新哈希表,多线程复制bucket到新哈希表,容量扩容到原来的2倍 |
| 链表插入 | 将新节点插入到链表尾部 | 将新节点插入到链表头部 | 将新节点插入到链表尾部 |
| 继承的类 | 继承abstractMap抽象类 |
继承Dictionary抽象类 |
继承abstractMap抽象类 |
| 实现的接口 | 实现Map接口 |
实现Map接口 |
实现ConcurrentMap接口 |
| 默认容量大小 | 16 | 11 | 16 |
| 默认负载因子 | 0.75 | 0.75 | 0.75 |
| 统计size方式 | 直接返回成员变量size |
直接返回成员变量count |
遍历CounterCell数组的值进行累加,最后加上baseCount的值即为size |